Session 13: Special Session on LLM
Housekeeping
- We will spend afternoon to focus on the projects.
🎯 Learning Objectives
By the end of this session, students will be able to:
- Describe how LLMs are trained generally and what LLMs do to produce language.
- Explain the benefits and drawbacks of using LLMs for linguistic annotation.
- Demonstrate/discuss potential impacts of prompts on the LLMs performance on linguistic annotation.
- Design an experiment to investigate LLMs output accuracy on a given annotation task.
Large Language Models
Chatting about ChatGPT
- Have you ever used ChatGPT or any other kind of LLM?
- What do you ask it to do?
Question!
What word would be suitable in the context?

Fill in the blank
How does it work?
- (Large) Language Models are statistical model.

Predicting next word
How does it work?
- Essentially, what it does is predicting the next word given the preceeding context.
- They are gigantic model (3-70B parameters for example; parameters analogous to neurons)
The picture taken from the following NVIDIA blog
How is it trained?
Why is it so intelligent…?
- Gigantic neural network (1B-70B)
- Gigantic corpus (Over 500GB - 2TB of texts; 35,000 times bigger than BROWN corpus)
- meaning roughly 300,000 different contexts of
chocolateit learns. - dog: 79 times * 35,000 = 23,700,000 occurrences
- meaning roughly 300,000 different contexts of
Prompt strategies
- Essentially, LLM produces next tokens given the preceding contexts.
- Looking at LLM this way,
prompt(the written instruction) conditions LLM to perform certain tasks.
→ Effective prompting approach may help LLM achieve higher performances
In-context learning
In-context learning refers to the use of examples embedded in the prompt as a way to augment the responses of LLM.
- Zero-shot: prompt without example
- One-shot: prompt with one example
- Few-short: prompt with a few examples
→ in-context learning, or few-shot prompting, can help us achieve better results without further “training” of the model.
LLM’s strengths and weeknesses in applied linguistics domain
- Scoring may not be a strengths (Mizumoto & Eguchi, 2023)
- However, annotation could be done better
- Move-step analysis (Kim & Lu, 2024)
- Linguistic accuracy analysis (Mizumoto et al., 2024)
Annotating move-steps in academic paper introduction
Kim & Lu (2024) examined the use of GPT to annotate discourse move.
What is discourse move and steps?
- Conventional rhetorical stages in writing:
| Move | Description |
|---|---|
| Move 1 | Establishing a research territory |
| Move 2 | Establishing a niche |
| Move 3 | Presenting the present work via some steps |
Kim & Lu’s validation process
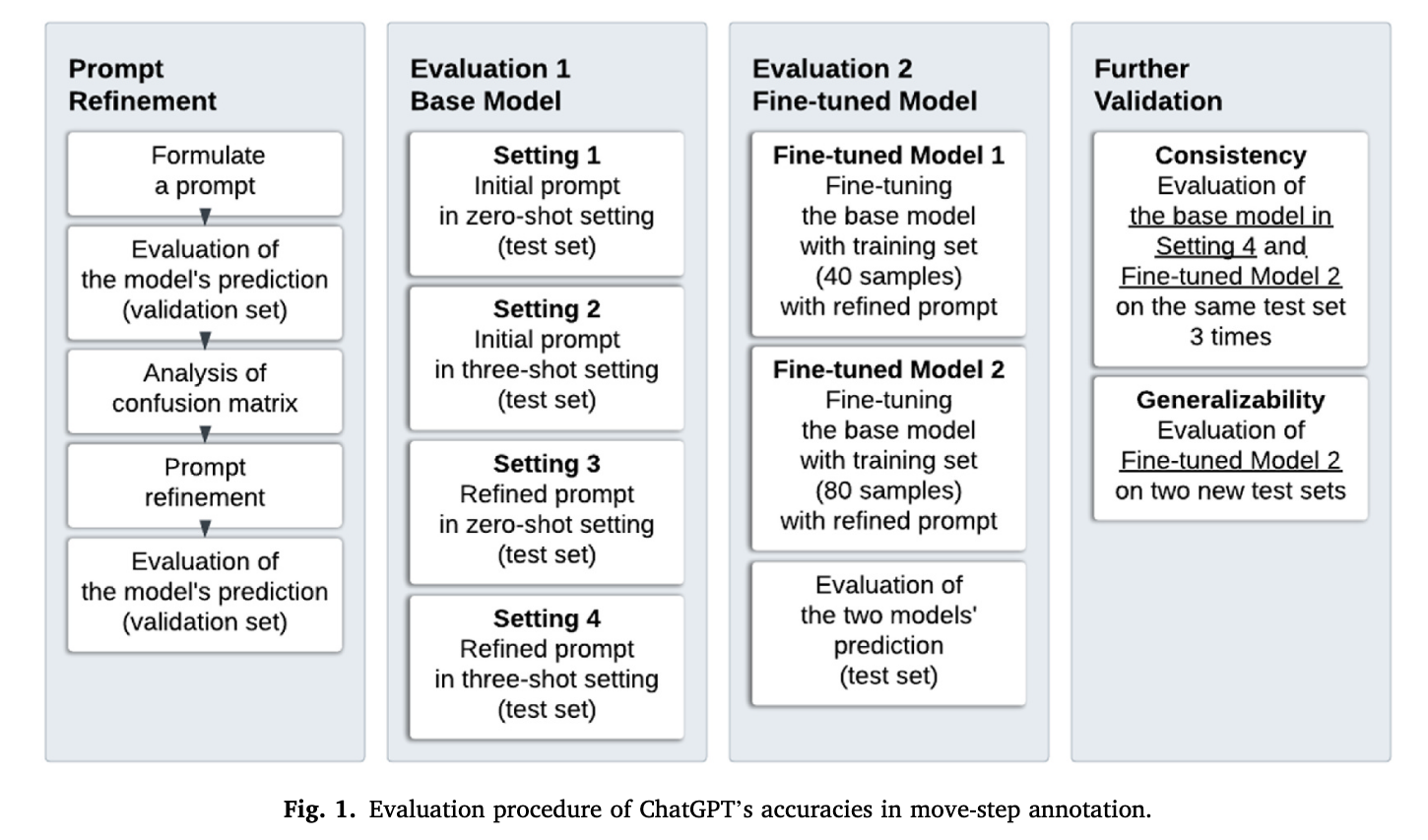
validation-process
Precision, Recall, and F1
Remember COVID test…
- You have
True Positive (TP),True Negative (TN),False Positive (FP), andFalse Negative (FN).
| \(Yes_{pred}\) | \(No_{pred}\) | |
|---|---|---|
| \(Yes_{true}\) | TP | FN |
| \(No_{true}\) | FP | TN |
Precision, Recall, and F1
- Precision = \(TP \over TP + FP\)
- (How much of retrieved YES actually YES?)
- Recall = \(TP \over TP + FN\)
- (How much of actual YES is retrieved?)
- F1 score = \({ (2 \times \text{Precision} \times \text{Recall})} \over {\text{Precision} + \text{Recall}}\)
Result - Move
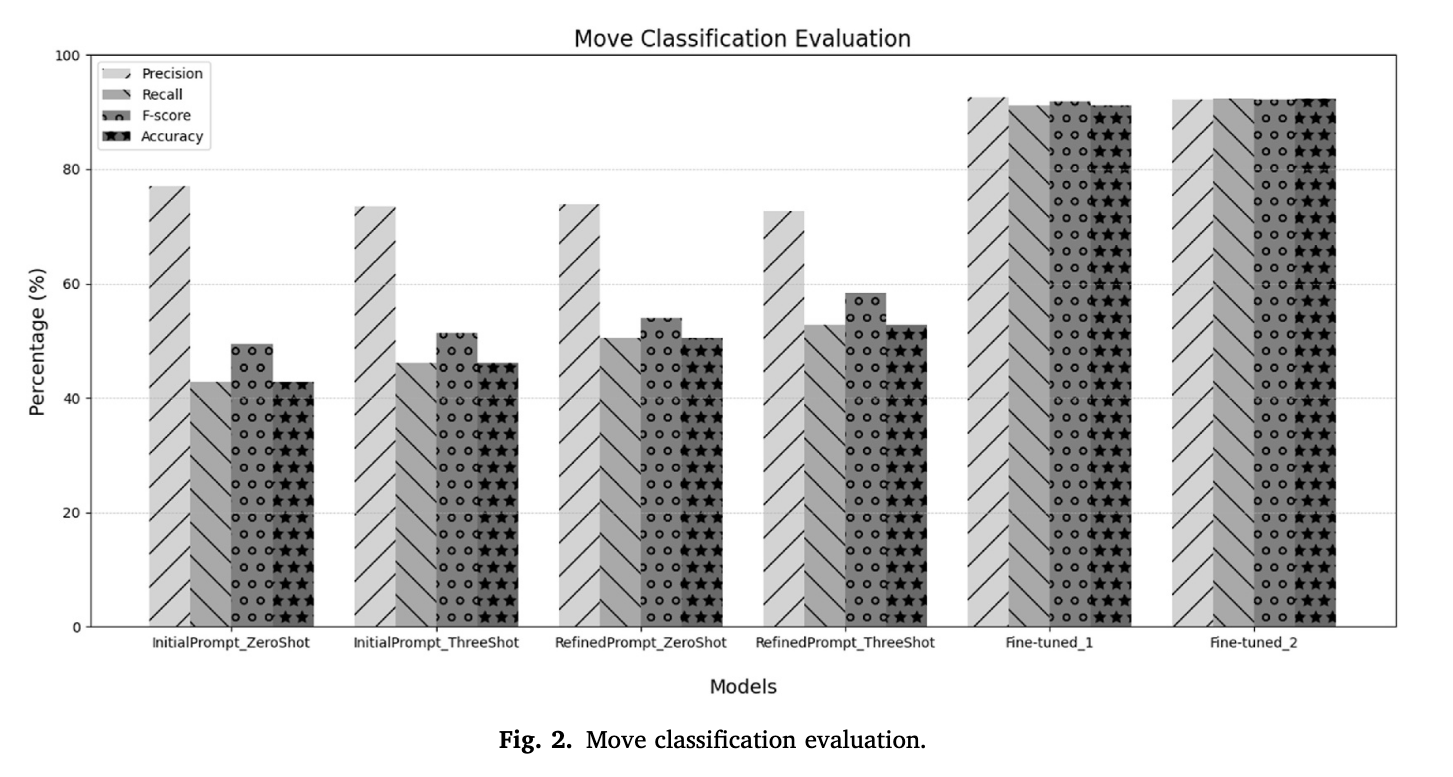
Almost perfect when fine-tuned
Result - Step
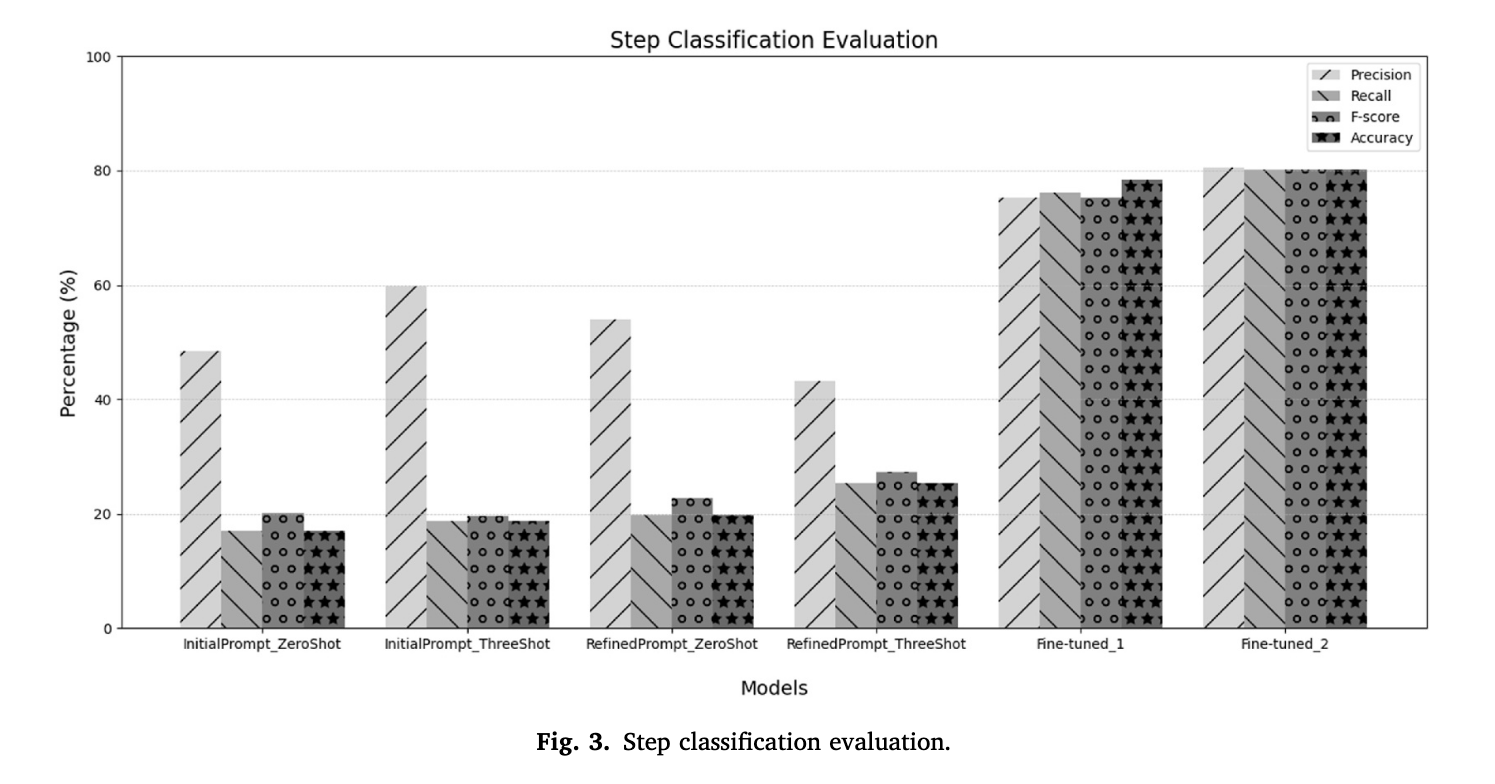
step analysis can be difficult
Mizumoto et al. (2024)
RQ1: To what extent is the accuracy evaluation by ChatGPT comparable to that conducted by human evaluators?
RQ2: How does the accuracy evaluation by ChatGPT compare to Grammarly?
Corpus
- the Cambridge Learner Corpus First Certificate in English (CLC FCE) dataset (Yannakoudakis et al., 2011).
- Freely available corpus with error tags and metadata:
- L1 (first language)
- age
- the overall score
Why this corpus?
- One of the few openly available error tagged corpus.
- Making it a “gold standard” for evaluating accuracy.
Error tagged corpus
- 80 types of errors were tagged
| No. | Code | Error Type |
|---|---|---|
| 6 | <AGV> |
Verb agreement |
| 7 | <AS> |
Argument structure |
| 10 | <CL> |
Collocation |
| 11 | <CN> |
Noun countability |
| 28 | <FV> |
Verb form |
| 31 | <ID> |
Idiom |
| 37 | <L> |
Register |
| 64 | <TV> |
Verb tense |
| 76 | <W> |
Word order |
| 61 | <S> |
Spelling (non-word) |
XML format
- The corpus is provided in XML (Extensible Markup Language) format
<?xml version="1.0" encoding="UTF-8"?>
<learner><head sortkey="TR160*0100*2000*01">
<candidate><personnel><language>Chinese</language><age>21-25</age></personnel><score>17.0</score></candidate>
<text>
<answer1>
<question_number>1</question_number>
<exam_score>2.2</exam_score>
<coded_answer>
<p>Dear <NS type="RN"><i>Madam</i><c>Ms</c></NS> Helen Ryan,</p>
... (More text here)
</coded_answer>
</answer1>
</text>
</head></learner>Participants
- 232 learners
- 86 Korean
- 80 Japanese
- 66 Chinese
Text cleaning
- They focused on Task 1 (letter writing)
- Etracted each sentence as one row in a data
- Removed metadata and error tags
The dataset
The dataset looked as follows:
- you have hand-tagged dataset
- clean dataset without any correction

Dataset view
Measures for accuracy
- Counted errors and words from the human-annotated corpus
- Accuracy is operationally defined as errors per 100 words
Evaluation of GPT-4 correction
- Sent each sentence with following prompt:
Reply with a corrected version of the input sentence with all grammatical, spelling, and punctuation errors fixed. Be strict about the possible errors. If there are no errors, reply with a copy of the original sentence. Then, provide the number of errors.
Input sentence: {each line of sentence}
Corrected sentence:
Number of errors:Distribution of error per 100 words
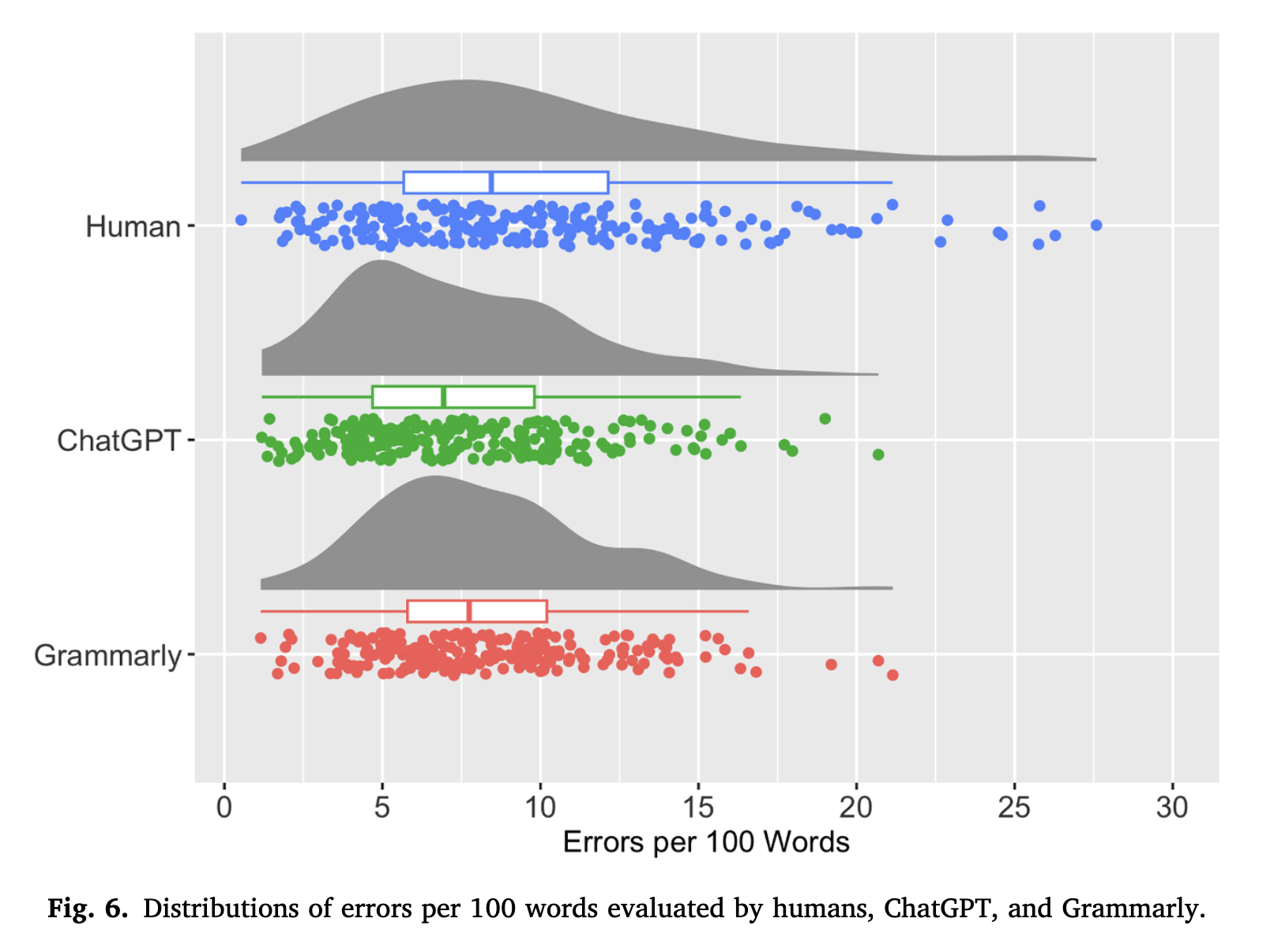
Errors per 100 words
Correlations among human, GPT, and Grammarly
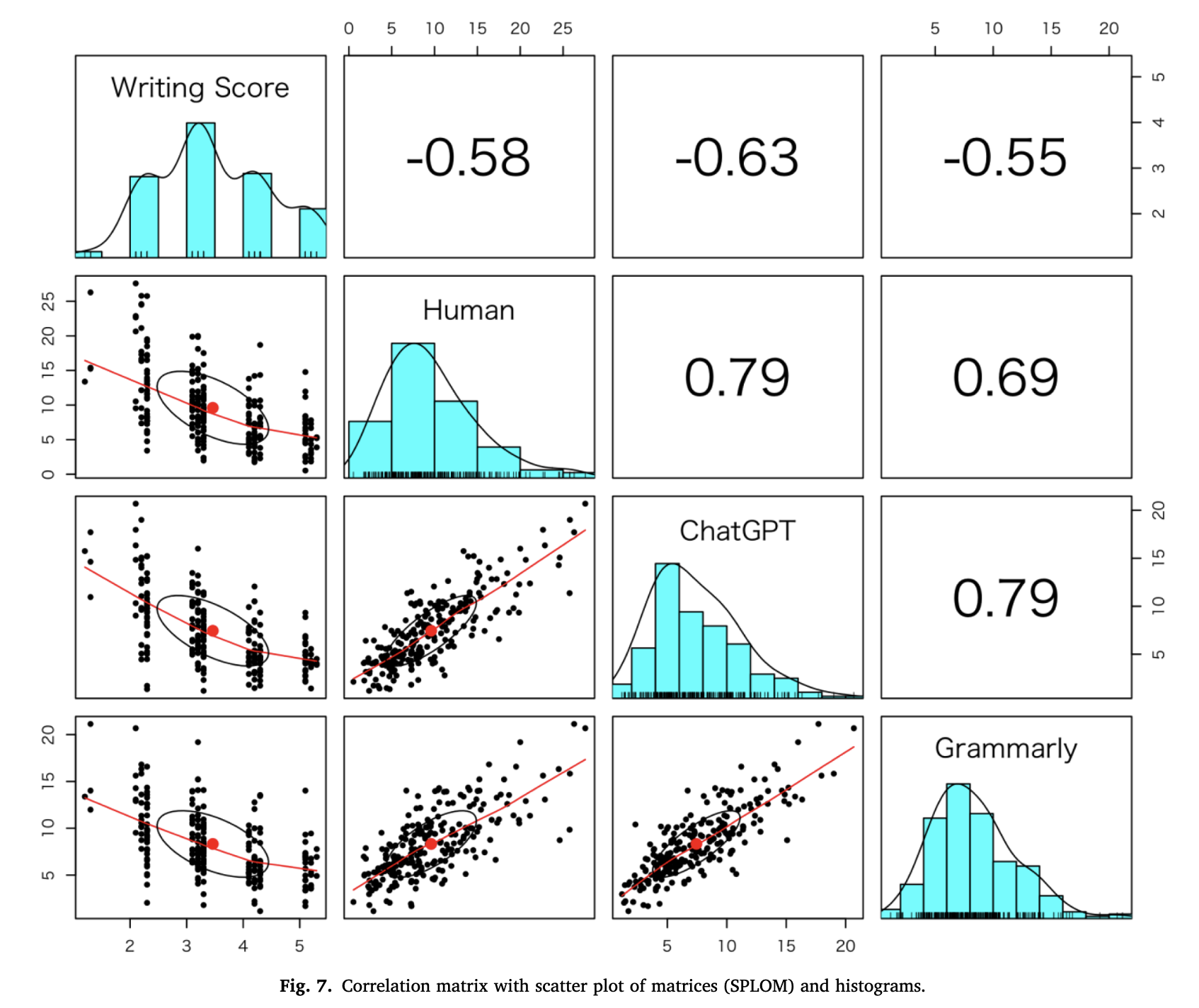
Correlations
Summary of findings
- Correlation with manual error tag: GPT > Grammarly
- Correlation with proficiency score: GPT > Grammarly
Take-away
- Corpus research requires cleaning of the corpus.
Let’s try
- First, download the CLC FCE dataset.
Linguistic Data Analysis I