Session 2: Corpus as a scientific method
Housekeeping
Session overview
We will talk about:
- Why we bother the corpus data?
- What it can tell us?
- How can we describe corpus as a scientific method
🎯 Learning Objectives
By the end of this session, students will be able to:
- Define corpus linguistics as an empirical methodology
- Explain key limitations of introspection in linguistic research
- Describe the role of frequency data and patterns in corpus analysis
- Identify and explain the basic steps in corpus-based research
- Reflect on their own stance toward data, intuition, and linguistic evidence
Corpus linguistics: Definition
Corpus linguistics
the investigation of linguistic research question
that have been framed in terms of the conditional distribution of linguisitc phenomena
in a linguistic corpus.
(Stefanowitsch, 2020, p. 56)
A linguistic Corpus
A linguistic corpus is:
- searchable digital collection of
- real-world language use
- often accompanied by meta-data describing the contextual parameters
→ A corpus documents “recorded observation of language behavior”
Why we bother with corpus?
when we can ask native speakers?
Common criticism to corpus linguistics
- Corpus documents performance not competence
- Corpus is incomplete
- It provides language forms but not meaning
- Corpus does not give negative evidence
→ First two points are worth elaborating.
Some researchers (particulary generative linguists) say…
- Corpus may not tell us about “competence”
- There is an assumption that “competence” (Language Acquisition Device) exists
- Performance data is too noisy to get to the actual competence
Some researchers (particulary generative linguists) say…
- Corpus is imcomplete…
- because corpus size is finite we cannot really tap into what native speakers will be able to say about the language
→ Corpus linguists respectfully disagree with these statements.
Why Can’t We Trust Our Intuition?
Guess the frequency! Test your intuition
Rank the following words by frequency in iWeb (14 billion word Web Corpus):
- the
- obvious
- dog
- absolutely
- meaningful
- chair
- and
Don’t turn to next slide until you finish sorting!
The frequency rank in iWeb corpus
| word | freq | freq per million |
|---|---|---|
| the | 746240010 | 53,332.79 |
| and | 387613768 | 27,666.94 |
| dog | 1447231 | 103.30 |
| absolutely | 1027853 | 73.37 |
| obvious | 715011 | 51.04 |
| chair | 621975 | 44.40 |
| meaningful | 297635 | 21.24 |
Test Your Intuition - 2
Is the following expressions grammatical? Yes or No?
- different from
- different than
- different to
What corpus has to say about them?
- Given this data, how would you describe the pattern?
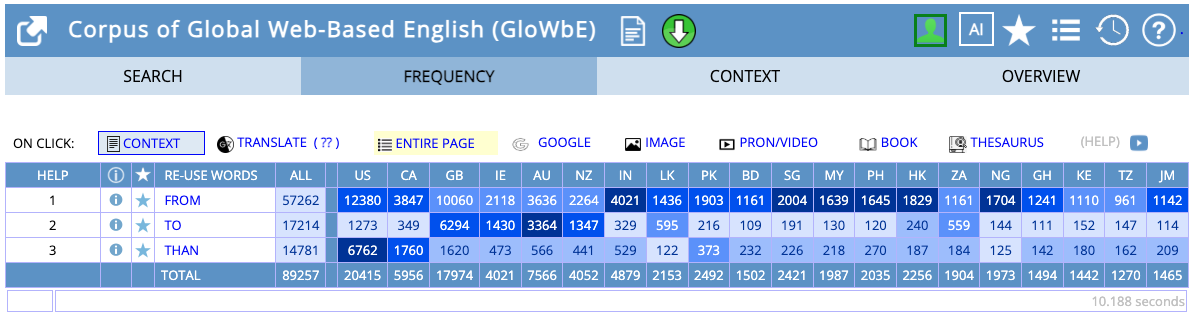
different + from/to/than
Your intuition may have failed because:
- We notice unusual things, not common ones
- Language frequency AND our physical world are different
- Our intuition is also affected by our other sensory modes and cognitive mechanisms
Reliability of intuited “data”
- Intuited data is vulnerable
- No one experienced every linguistic varieties spoken in the world.
- The cognitive process to judge grammaticality will be different from usual language processing interpreting the “meaning”.
It doesn’t matter the N
- I searched this construction over News on the web (NOW) corpus which is 22.5 billion+ corpus across 20 countries.
- It is not actually exclusive to the British construction.
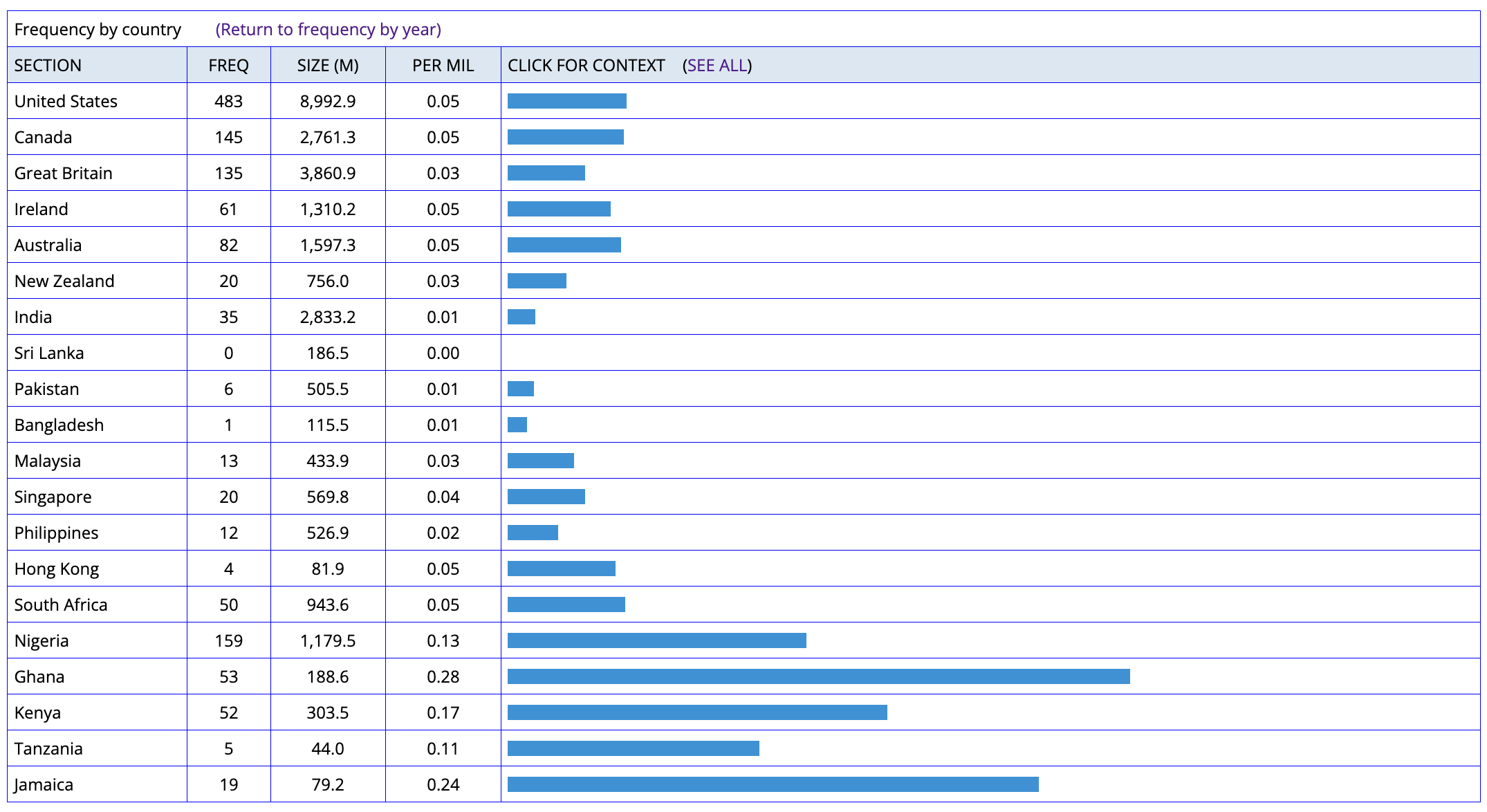 See the result here
See the result here
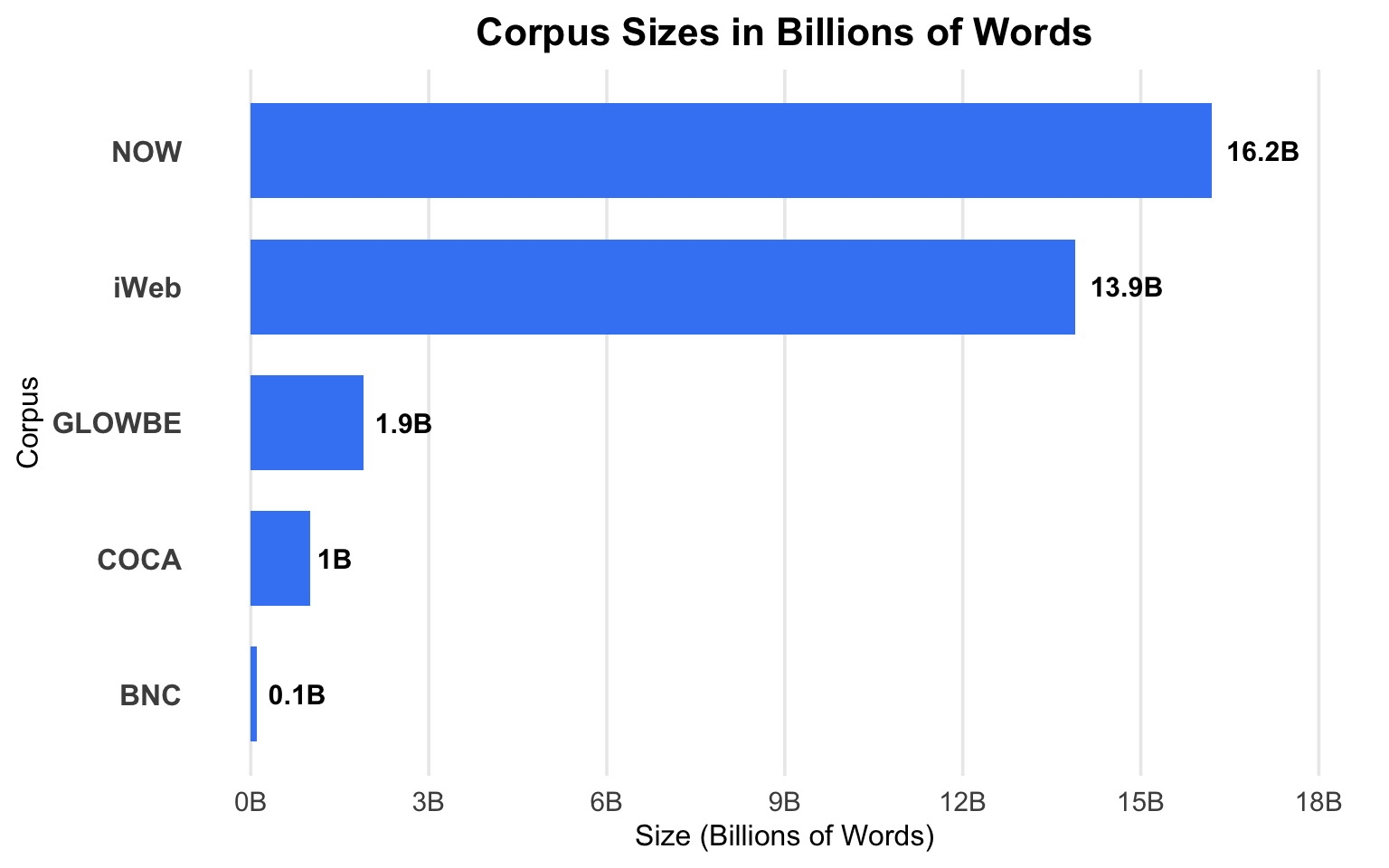
Corpus Size Comparison
Limitations of Corpus
- Corpus is incomplete; impossible to reflect all the linguistic variations.
- provides distributional information, but not interpretation
- limited contextual information
- does not tell us about language processing
Corpus has to be selected in relation to the purpose of the study
Summary
- Corpus can provide information about how people are actually using the language
- May not be complete; but big enough to tell us something more than a small group of individuals can say about the language use
- Prescriptive vs Descriptive
- Corpus also has limitation
- Corpus is finite
- Corpus data needs to be interpreted (but better than intuiting).
Any questions?
Part 2: Corpus linguistics as a scientific method
What do you think is important in scientific process?
- So far we have talked about how corpus can be useful as a method of inquiry.
- We have not talked about how corpus can be integrated in the research process.
→ Let’s talk about general research cycle then we will go over with corpus examples.
Scientific research cycle
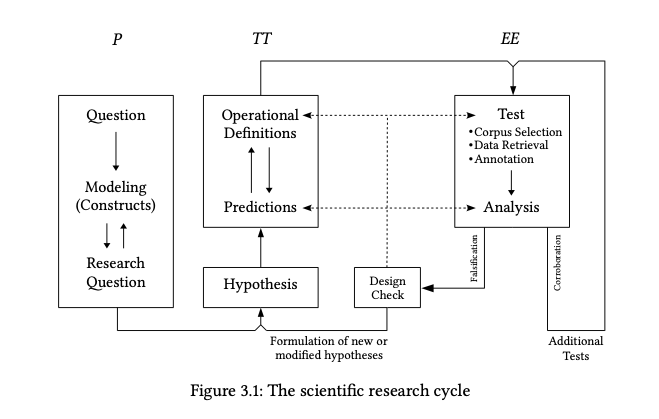
Research Process
Let’s do it together
- Verbalize your initial questions
- Formulate research questions
- Formulate research hypothesis
- Operationalize - defining the construct so we can measure
- Test it
- Evaluate the hypothesis
Step 1: Starting from question or curiosity
Research is mostly driven by curiosity.
- Is “sort of” used exclusively in spoken discourse? If not what written genre might include this?
- What adjectives are commonly used to modify “stair”?
- Where is the contraction form “gonna” more likely to be used in English?
Your turn
- In pair, exchange what you’ve wondered about the English language use in context.
- Focus on vocabulary, grammar, and possibly discourse
- We cannot unfortunately look at phonetics/phonology in this class…
- After sharing your curiosity, we will then use that to frame the research question.
Step 2: Turning curiosity into research question
A research question often involves relations between two or more constructs.
What are constructs?
Constructs are simply theoretical concepts we are interested in researching.
Linguistic constructs
- Words, Grammar, etc.
Extra-linguistic constructs
- TIME
- REGION
- GENRE
- PROFICIENCY LEVEL
Research question templates
In corpus-driven linguistic research, we tend to ask following questions:
- How does the frequency of word X change over time?
- How does the frequency of word X differ across text types Z?
- What is the frequency distribution of grammatical pattern X across different text types?
- What are the typical contexts in which expression X appears based on concordance analysis?
- How do different varieties of language Y (e.g., British vs. American English) differ in frequency and contexts of feature X?
- How does register (formal/informal) affect both the frequency and typical contexts of linguistic feature X?
Your turn:
- In the same pair, try turning your curiosity into formalized research question.
- Share the research questions to class.
Step 3: Turning question into hypothesis
Research Q: “Is the expression ‘gonna’ more frequent in informal genres?”
Hypothesis: “I expect ‘gonna’ to occur more frequently in TV/Movie subtitles than in Magazine texts because…”
Your turn - Writing hypothesis
In the same pair, you will be writing your hypothesis.
Template: “I expect [specific pattern] because [reasoning based on experience/knowledge]”
Step 4: Choosing a corpus based on your research question and hypothesis
How can I select the one for my research?
Three key properties of corpus
- Authentic:
- Corpus reflects real-language use
- Representative:
- Corpus should be sampled to reflect some portion of language use.
- Large:
- Corpus should be in sufficient size to allow investigation
Authenticity
- It has to be authentic language use (= language used for real communication)
- No invented sentences
- No fake data or simulation
- BUT… Debate on authenticity
- How about elicited data?
- Particularly relevant to learner corpora
- Timed essay writing for English exam
Representativeness
- How do researchers try to take representative sample of language use?
- What makes a corpus representative?
Representative in relation to your purpose
- Representativeness is evaluated based on
- coverage of important situational variables
- relative size in the corpus (balances)
- Think of a stratified random sampling approach
Describing situational variables
Discuss in pair/group:
If you were to create following corpus, what should you include in your corpus? Choose one and brainstorm the data sources you need to collect.
- how English is currently used in the US
- how English/Japanese is used in US/Japanese universities
- how certain dialect changes overtime
Corpus Of Contemporary American (COCA)
| Genre | # texts | # words | Explanation |
|---|---|---|---|
| Spoken | 44,803 | 127,396,932 | Transcripts of unscripted conversation from more than 150 different TV and radio programs (examples: All Things Considered (NPR), Newshour (PBS), Good Morning America (ABC), Oprah) |
| Fiction | 25,992 | 119,505,305 | Short stories and plays from literary magazines, children’s magazines, popular magazines, first chapters of first edition books 1990-present, and fan fiction. |
| Magazines | 86,292 | 127,352,030 | Nearly 100 different magazines, with a good mix between specific domains like news, health, home and gardening, women, financial, religion, sports, etc. |
| Newspapers | 90,243 | 122,958,016 | Newspapers from across the US, including: USA Today, New York Times, Atlanta Journal Constitution, San Francisco Chronicle, etc. Good mix between different sections of the newspaper, such as local news, opinion, sports, financial, etc. |
| Academic | 26,137 | 120,988,361 | More than 200 different peer-reviewed journals. These cover the full range of academic disciplines, with a good balance among education, social sciences, history, humanities, law, medicine, philosophy/religion, science/technology, and business |
Corpus of Contemporary American (COCA)
| Genre | # texts | # words | Explanation |
|---|---|---|---|
| Web (Genl) | 88,989 | 129,899,427 | Classified into the web genres of academic, argument, fiction, info, instruction, legal, news, personal, promotion, review web pages (by Serge Sharoff). Taken from the US portion of the GloWbE corpus. |
| Web (Blog) | 98,748 | 125,496,216 | Texts that were classified by Google as being blogs. Further classified into the web genres of academic, argument, fiction, info, instruction, legal, news, personal, promotion, review web pages. Taken from the US portion of the GloWbE corpus. |
| TV/Movies | 23,975 | 129,293,467 | Subtitles from OpenSubtitles.org, and later the TV and Movies corpora. Studies have shown that the language from these shows and movies is even more colloquial / core than the data in actual “spoken corpora”. |
| Total | 485,179 | 1,002,889,754 |
British Academic Written English (Alsop & Nesi, 2009)
A excellent example of a specialized corpus.
- A corpus documenting about 2,700 university written assignments in the U.K.
- 30 disiplines, 13 genre families
- Four course levels (freshman to MA level)
- Both Distinction (A) and Merit (B)
BAWE disciplinary group
| Disciplinary group | Disciplines | Level 1 | Level 2 | Level 3 | Level 4 | Sum |
|---|---|---|---|---|---|---|
| Arts and Humanities (AH) | Linguistics, English, Philosophy, History, Classics, Archaeology, Comparative American Studies, Other | 231 | 225 | 160 | 77 | 693 |
| Life Sciences (LS) | Biology, Agriculture, Food Sciences, Psychology, Health, Medicine | 172 | 183 | 106 | 193 | 654 |
| Physical Sciences (PS) | Engineering, Chemistry, Computer Science, Physics, Mathematics, Meteorology, Cybernetics & Electronics, Planning, Architecture | 181 | 146 | 156 | 95 | 578 |
| Social Sciences (SS) | Business, Law, Sociology, Politics, Economics, Hospitality Leisure & Tourism Management, Anthropology, Publishing | 203 | 196 | 159 | 202 | 760 |
| Sum | 787 | 750 | 581 | 567 | 2,685 |
BAWE genre family
| Social purpose | Genre family | Level 1 | Level 2 | Level 3 | Level 4 | Sum |
|---|---|---|---|---|---|---|
| Demonstrating knowledge and understanding | exercise | 28 | 20 | 27 | 27 | 102 |
| explanation | 72 | 54 | 33 | 26 | 185 | |
| Developing powers of independent reasoning | critique | 75 | 78 | 67 | 87 | 307 |
| essay | 398 | 357 | 263 | 184 | 1,202 | |
| Building research skills | literature survey | 10 | 6 | 7 | 9 | 32 |
| methodology recount | 106 | 114 | 43 | 60 | 323 | |
| research report | 7 | 16 | 22 | 16 | 61 | |
| Preparing for professional practice | case study | 26 | 30 | 34 | 98 | 188 |
| design specification | 24 | 19 | 35 | 11 | 89 | |
| problem question | 12 | 18 | 5 | 2 | 37 | |
| proposal | 10 | 18 | 8 | 34 | 70 | |
| Writing for oneself and others | empathy writing | 4 | 2 | 17 | 5 | 28 |
| narrative recount | 15 | 18 | 20 | 8 | 61 | |
| Sum | 787 | 750 | 581 | 567 | 2,685 |
Corpus Representativeness
Multiple factors affecting linguistic variations can be used to balance corpus sampling:
- Linguistic variation = “to any form of language delineable from other forms along cultural, linguistic or demographic criteria” (Stefanowitsch, 2020, p. 28)
- genre
- register
- style
But see Biber and Conrad (2019) for different definitions of each factor.
Genre
- category of speech event or text defined in terms of their communicative purpose in culture
- recipe
- manuals
- academic paper
- news report
- etc.
Register
- variety in a set of linguistic features associated with a particular situation of language use.
- register of:
- academic paper
- recipe
- register of:
Style
- Stefanowitsch defines: “the degrees of formality” (e.g. formal, informal, colloquial, humorous)
- Biber & Conrad (2019) linguistic variety often associated within a register or genre
- due to the author, specific speech community, etc.
In case of learner corpora
Additional variables such as:
- First language
- Second-language proficiency levels
- Their learning experiences
ICNALE
- International Corpus Network of Asian Learner of English (Ishikawa, 2013)
- One of the largest learner corpora (EFL learners in Asia)
- Subcorpora for different modalities available
- Monologic speech
- Dialogic speech
- Argumentative essay writing
- Extensive rating data is also available for subset of the data (GRA)
ICNALE
| Modules | Contents | # of participants | # of samples | # of words |
|---|---|---|---|---|
| Spoken Monologues (SM) | 60-seconds monologues about two ICNALE common topics | 1,100 | 4,400 | 500,000 |
| Spoken Dialogues (SD) | 30-40-minutes oral interviews including picture descriptions and role plays, and 3-5-minute follow-up L1 reflections. Interview tasks are related to two ICNALE common topics | 425 | 4,250 | 1,600,000 |
| Written Essays (WE) | 200-300-word essays about two ICNALE common topics | 2,800 | 5,600 | 1,300,000 |
| Edited Essays (EE) | Fully edited versions of learner essays about two ICNALE common topics. Rubric-based essay evaluation data is also included | 328 | 1,312 | 150,000 |
| Written Essays Plus (WEP) | 200-300-word essays about two ICNALE common topics collected from new Asian countries | 948 | 1,896 | 470,000 |
| Global Rating Archives (GRA) | + Ratings of 140 speeches and 140 essays by 80 raters with varied L1 and occupational backgrounds. + Plus fully edited versions of 140 essays |
280 samples × 80 raters | 22,400 | (Edited essays) 65,000 |
From Question to Corpus Choice
Let’s say you want to investigate the following question:
- “Is
passive construction(be + past participle) more frequent in formal genres?”
What information do you need in the corpus?
Try giving some answers in pairs.
Typical answer
- Has multiple genres (formal AND informal)
- Recent enough to include
passive construction(be + past participle) - Large enough to compare
Corpora in English-Corpora.org
Corpus Size Comparison
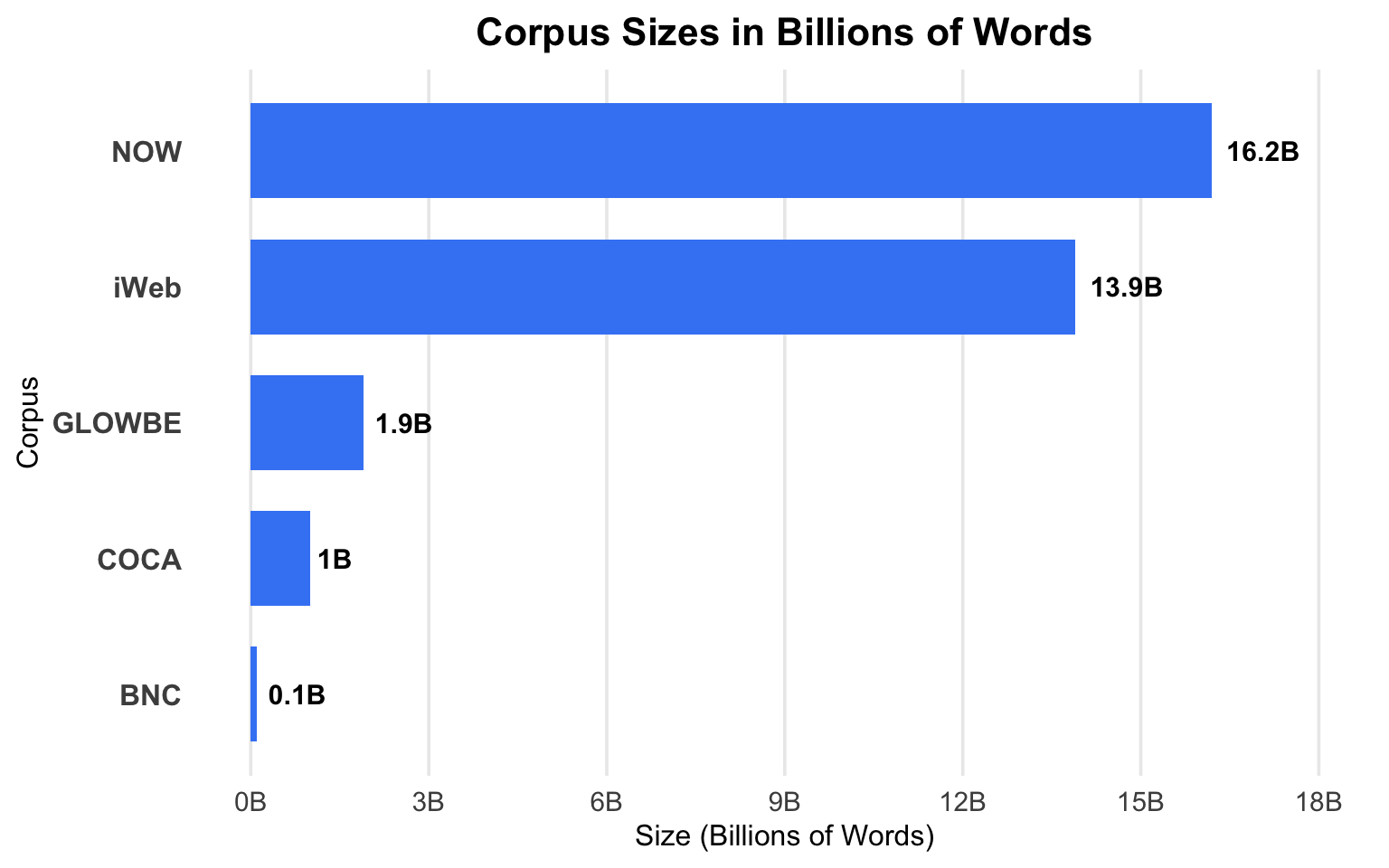
Gnowing Size - Good or bad?
The corpus is becoming larger and larger.
- Is this a good thing?
- Any drawbacks we might foresee?
Steps 4-6: In Session 3
- Operationalize = Define exactly what to search
- Test = Actually search the corpus
- Evaluate = Interpret your results
We’ll practice these with real searches in Session 3!
Reflection
- Did your view on the linguistic intuition change? If so how?
- Explain three key property of a linguistic corpus using examples.
Linguistic Data Analysis I