Session 5: Hands-on activity #2
Frequency list
Housekeeping
🎯 Learning Objectives
By the end of this session, you will be able to:
- Compute frequency of a single-word lexical item in reference corpora
- Derive vocabulary frequency list using concordancing software (e.g., AntConc)
- Apply tokenization on the Japanese language corpus for frequency analysis
- Conduct Lexical Profiling using a web-application or desktop application (e.g., AntWordProfiler)
Tasks
- Loading a corpus to AntConc
- Creating a frequency list
- Visualize frequency distributions
- Tokenize non-English language
- (If time left) Vocabulary profiling
Task 1: Loading a corpus to AntConc
Open AntConc
AntConc
AntConc window
AntConc2
Load a corpus
Now, let’s load a corpus.
- We will use BROWN Corpus.
Load-corpus
Task 2: Creating a frequency list
Word Frequency
Let’s now create a word frequency list from a corpus
Select
Wordanalysis optionSet
Min. FreqandMin. Range
- Min. Freq = the number of times the word should occur in the corpus
- Min. Range = the number of files in which the word should occur
- Hit
Start
Let’s try
- Set min. frequency = 3; min. range = 3
![Load-corpus]()
Saving the frequency list
- From
Filehitsave the current results
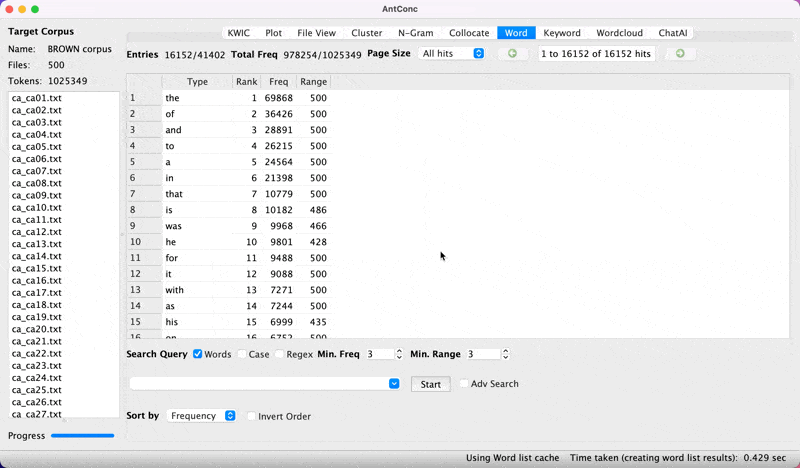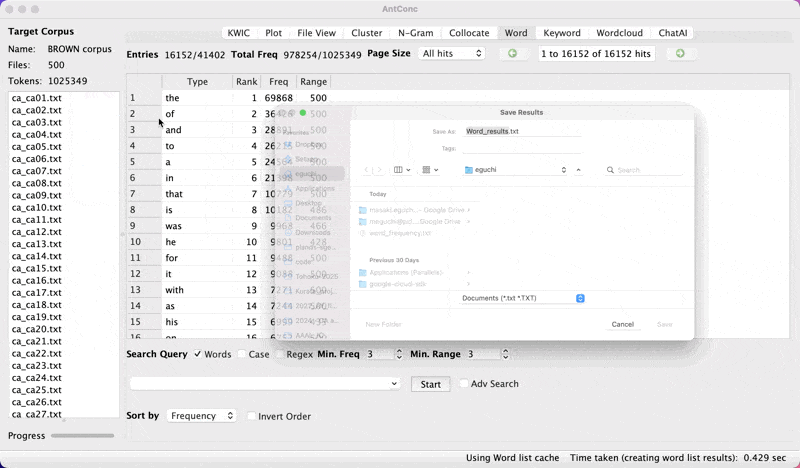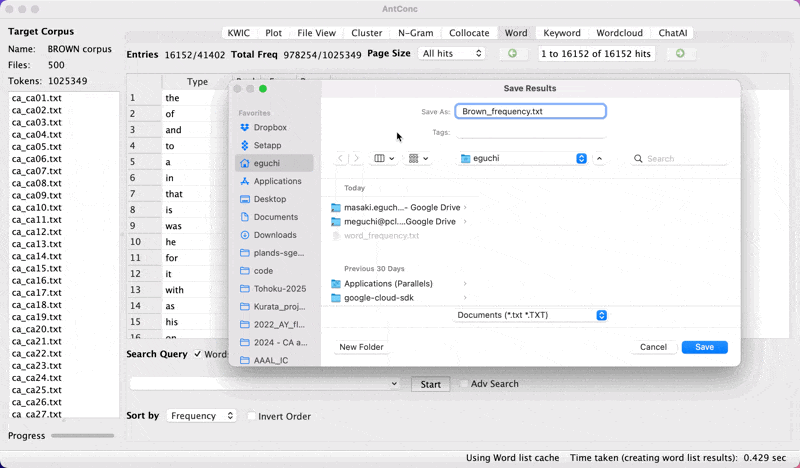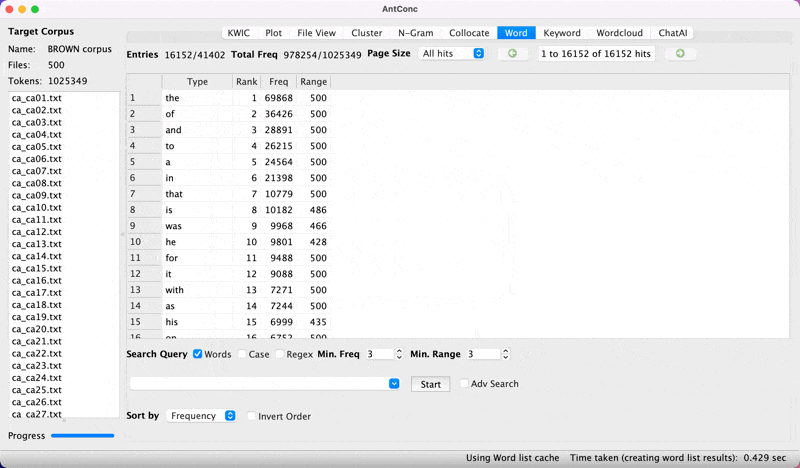
save-list
Frequency list
- We will use the BROWN frequency list in the next session.
Task 3: Plot frequencies
Visualizing frequency distributions
- Let’s now understand the distributions of words in BROWN corpus.
- Visit our simple-text-analyzer tool.
- Hit Frequency analysis and upload the frequency list.
Frequency Plot
- X-Axis = Group of 500/1,000/2,000 words
- Y-Axis = Average Frequency across all words in the band
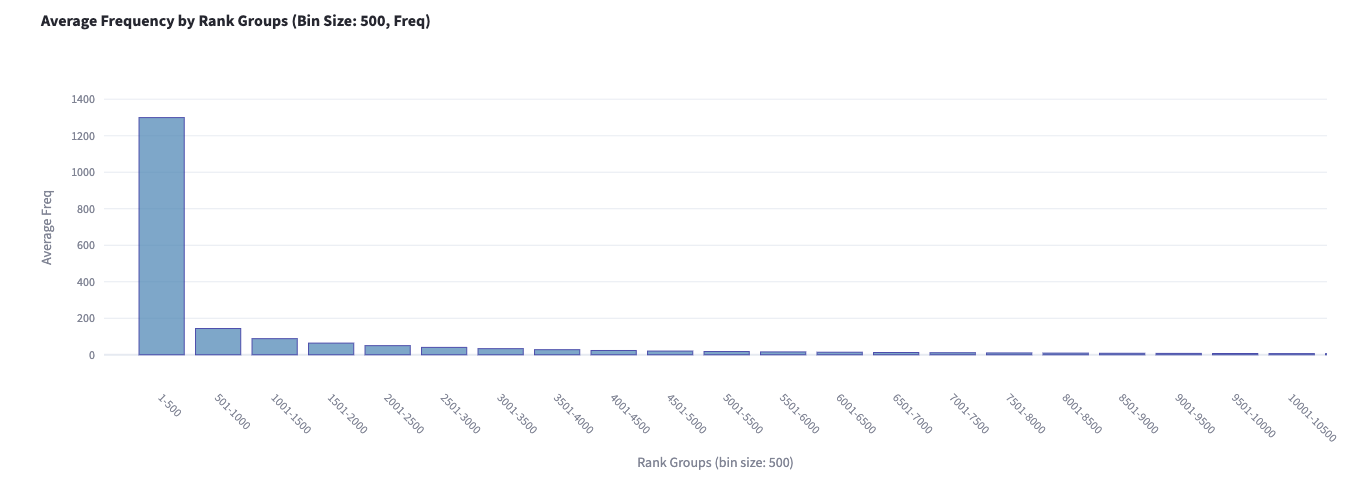
BROWN frequency
Discussion
- What do you learn from the previous bar graph?
- For each frequency band, what are the characteristics of the sample words you see?
Task 4: Creating frequency lists of Japanese
So far…
- Up to this point, we only dealt with the English language.
- Let’s try doing the same for Japanese.
- But we need to do something extra…
- Can you guess what that is?
- I am planning to eat Oysters after this intensive course.
- この短期集中講座が終わったら、カキを食べたいと思っています。
Tokenization
- English is very convenient in corpus analysis because of the white spaces.
- Asian languages have completely different writing system from Indo-European language, and it makes it difficult to
tokenizetexts into words.
English text
I am planning to eat Oysters after this intensive course.Japanese text
この短期集中講座が終わったら、カキを食べたいと思っています。Tokenization
Tokenization= segmenting running text into wordsIt needs more advanced statistical algorithms for Asian languages.
- How would you chunk these
この短期集中講座が終わったら、カキを食べたいと思っています。
Tokenization with TagAnt
- TagAnt is a free tool (again developped by Laurence ANTHONY) to conduct tokenization (and POS tagging).
- It uses modern natural language processing tool (called spaCy) to tokenize input texts.
Tokenizing Japanese
- Download and open
TagAnt.![TagAnt sections]()
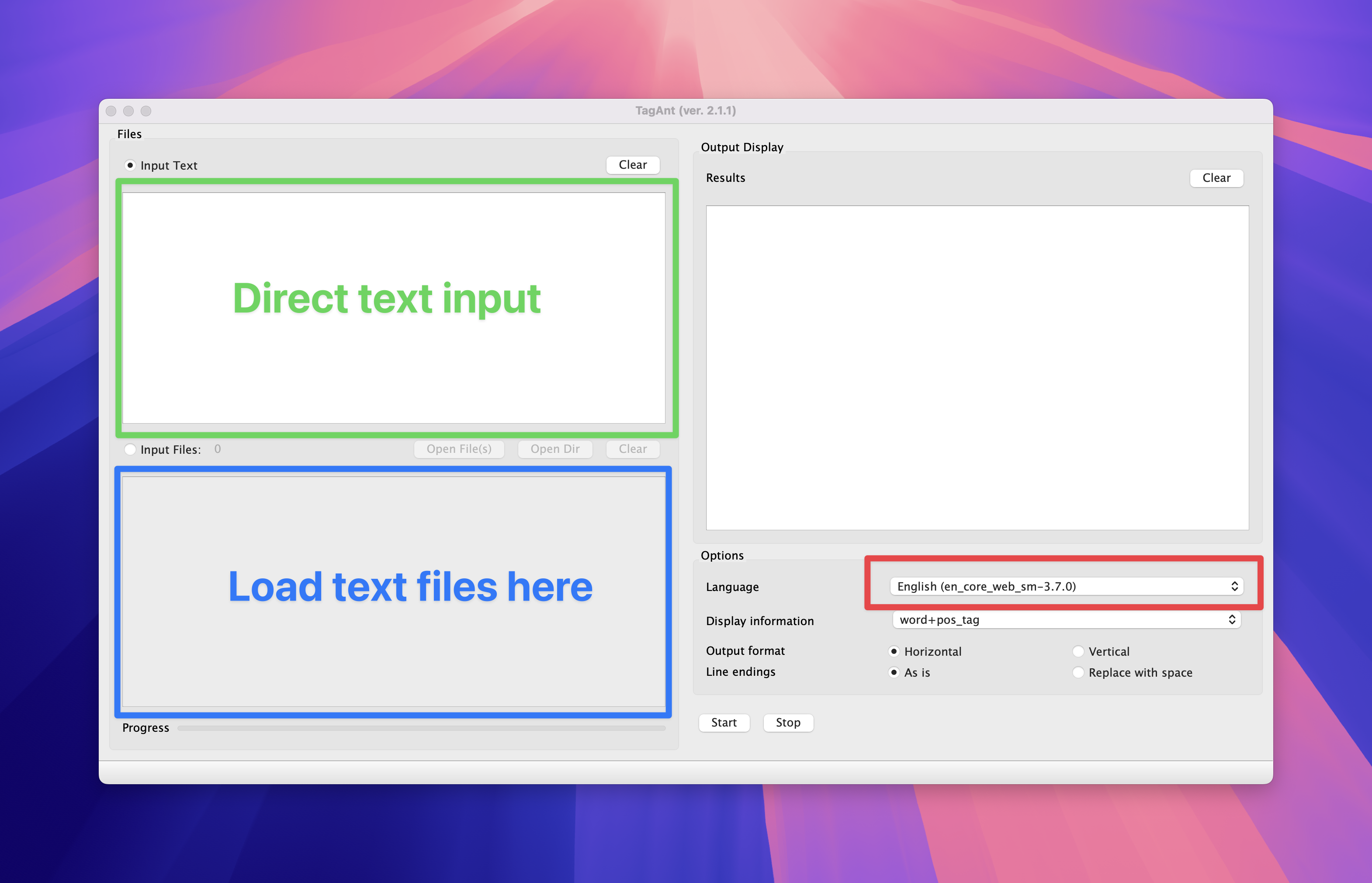
Tokenizing Japanese
- Input text
- Select language.
- Select Output format.
Result of TagAnt segmentation
You can choose from two output formats.
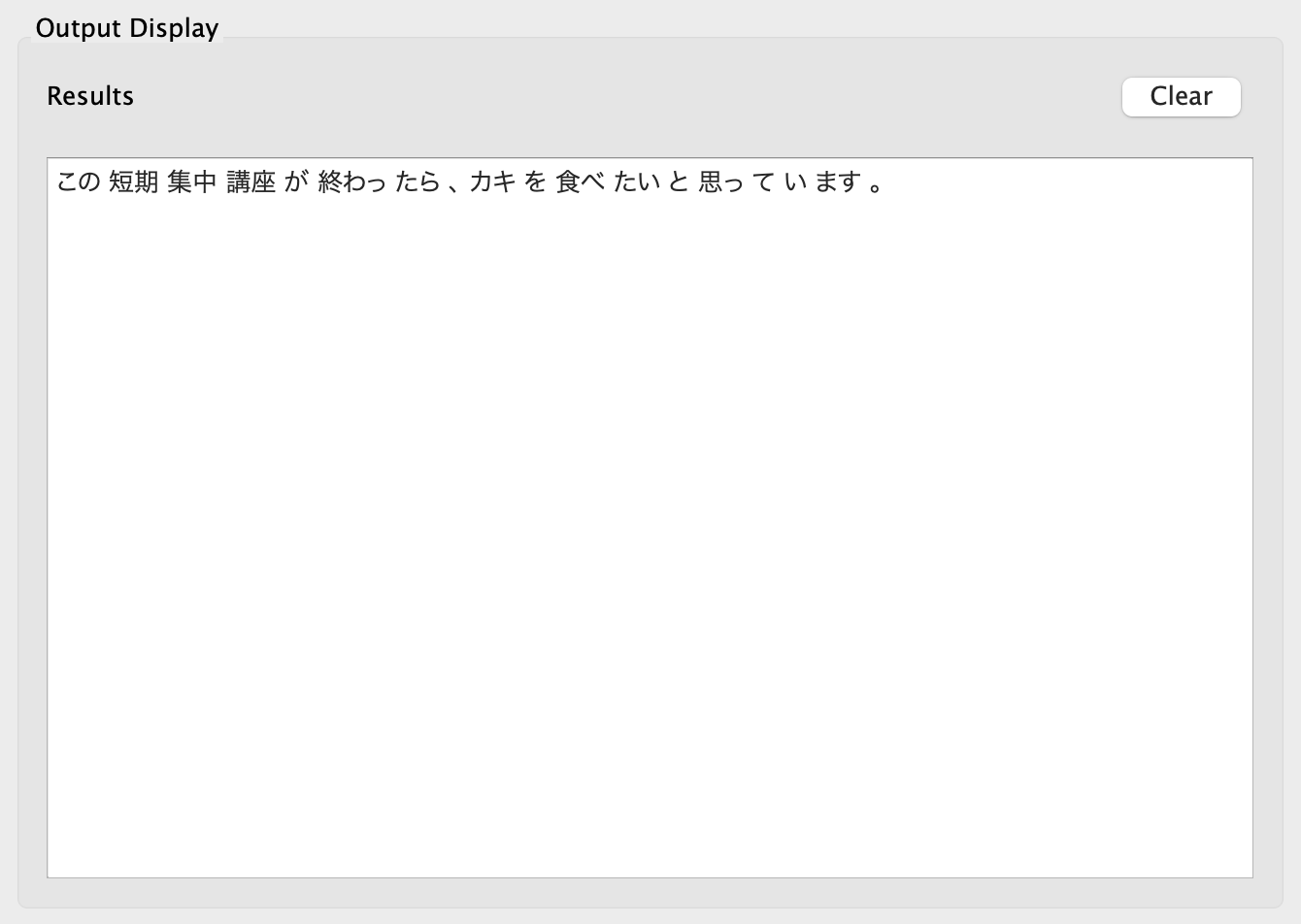
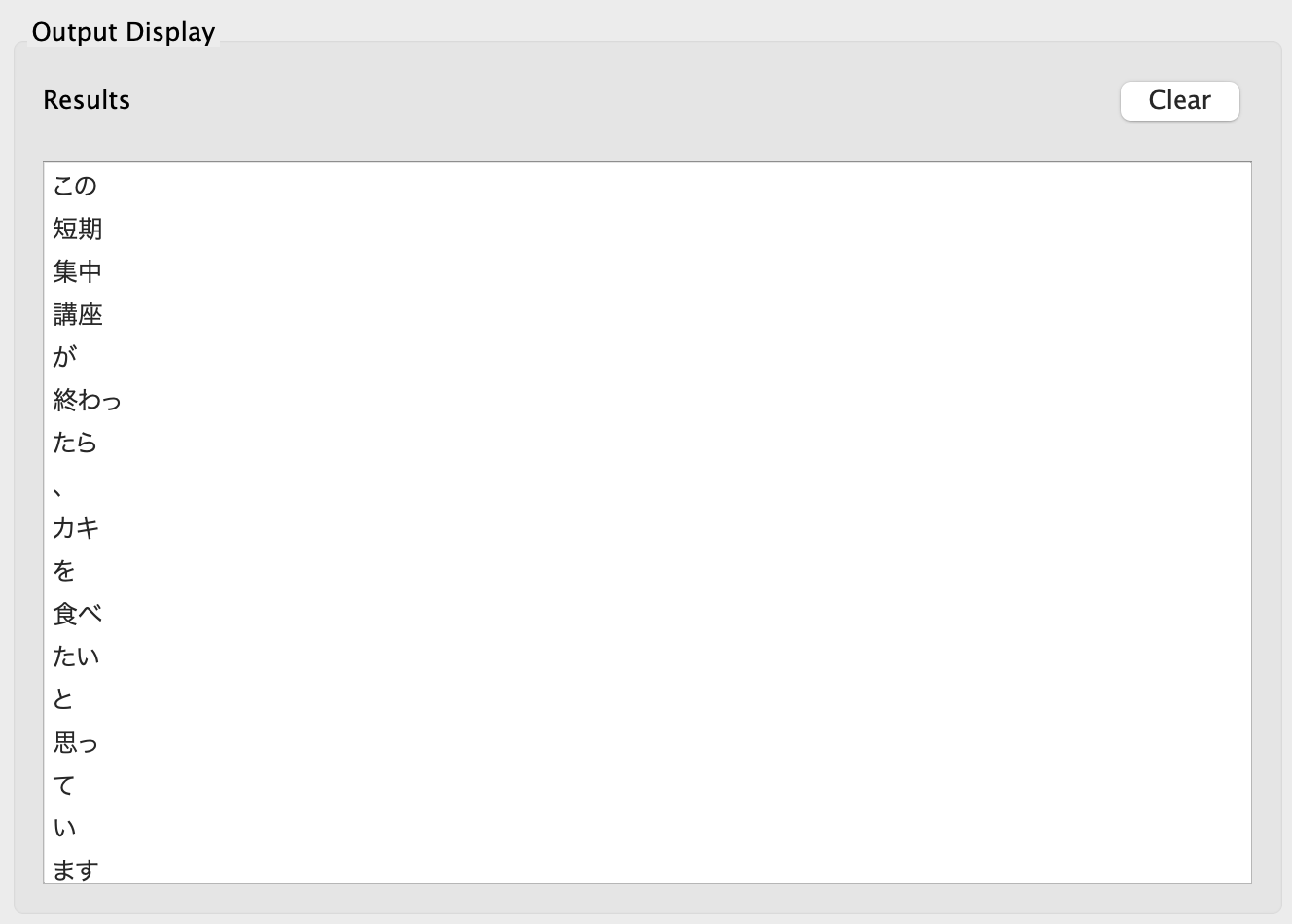
Part-Of-Speech Tagging in TagAnt
TagAnt can do more than tokenization.
It allows you to automatically annotate the token for Part-Of-Speech (POS).
POS = Grammatical category of lexical items (NOUN, VERB, etc.)
Choosing the right format for POS representation
You can ask TagAnt for different output formats.
For now, let’s choose
word+POS.
この短期集中講座が終わったら、カキを食べたいと思っています。この_DET 短期_NOUN 集中_NOUN 講座_NOUN が_ADP 終わっ_VERB たら_AUX 、_PUNCT カキ_NOUN を_ADP 食べ_VERB たい_AUX と_ADP 思っ_VERB て_SCONJ い_VERB ます_AUX 。_PUNCT
Now try different options…
- Let’s analyze your own example with the following:
word+posword+pos_tagword+lemmaword+pos+lemma
- What do these choice give you? Share it with your neighbor.
Other choices and expected results
| Display Information | Example |
|---|---|
| word | カキ を 食べ たい |
| word+pos | カキ_NOUN を_ADP 食べ_VERB たい_AUX |
| word+pos_tag | カキ_名詞-普通名詞-一般 を_助詞-格助詞 食べ_動詞-一般 たい_助動詞 |
| word+lemma | カキ_カキ を_を 食べ_食べる たい_たい |
Questions?
Corpus Lab 2: Task 1
Instruction
Task 1: Compile a Japanese Word Frequency list
Task
Compile a Japanese frequency list based on a corpus.
Resource
- Download a Japanese text
Aozora 500from Google Drive. - Use AntConc, TagAnt, and Simple Text Analyzer.
Submission
- Submit a frequency list
.tsvor.txt. - Description of word frequency pattern in Japanese.
Success Criteria
Your submission …
Task 4: Vocabulary Profiling
Due to possible time limitation, let’s come back to this if we have time at the end of session 6.
Vocabulary Profiling
- Vocabulary profiling is a technique to use corpus frequency to understand characteristics of vocabulary use in the input text
- For lexical sophistication measure
- LFP, Beyond 2000
- For lexical coverage
- How many words do readers/listeners need to know in order to comprehend the text (90, 95, or 98% coverage)
Vocabulary Profiling tools
- RANGE program
- VocabProfiler in LexTutor
- AntWordProfiler (desktop; multi-language)
- New Word Levels Checker
What we’ve covered
- Creating frequency list
- Tokenizing Japanese texts
- Conducting Part-Of-Speech tagging
Linguistic Data Analysis I