
[1] 0.25Session 7: Multiword Units
Masaki EGUCHI, Ph.D.
Housekeeping
Session overview
- Recap for Corpus Lab 2
- Multiword Units - Definition and Operationalization
- Strengths of Association (SOA) measures
- Phraseological Complexity
Corpus Lab 2
Corpus Lab 2: Submission
- Task 1: Japanese Word Frequency List and small write-up (5 points)
- Task 2: Replication of Durrant’s analysis from Figure 4.19 (5 points)
- research question,
- hypothesis,
- plots, and
- results
- Task 3: Comparison of two texts in terms of lexical sophistication (5 points)
Corpus Lab 2: Task 1
Instruction
Task 1: Compile a Japanese Word Frequency list
Task
Compile a Japanese frequency list based on a corpus.
Resource
- Download a Japanese text
Aozora 500from Google Drive. - Use AntConc, TagAnt, and Simple Text Analyzer.
Submission for task 1
- Submit a frequency list
.tsvor.txt. - A short description of word frequency pattern in Japanese.
Success Criteria
Your submission …
Corpus Lab 2: Task 2
Instruction
Goal: to replicate analysis on GiG.
You will need to have access to both metadata file.
The corpus data is here.
About GiG meta data
- GiG metadata documents the necessary data to use for plotting
- Year Group (X-axis in Figure 4.19)
- Genre (grouping variable in Figure 4.19)

GiG Metadata
Writing up research question, hypothesis, and results
- Research question?
- Hypothesis: Write your own.
- Results: Write your own.
Success Criteria
Your submission …
Corpus Lab 2: Task 3
Comparing lexical characteristics of two texts
Goals
- Compare and contrast two texts along with several lexical diversity metrics
- Observe differences in single-word and multiword sophistication
Data
- Choose two texts from the ICNALE GRA
- If you are unsure, use choose from the following three files:
- GRA_PTJ0_124_ORIG.txt
- GRA_PTJ0_070_ORIG.txt
- GRA_PTJ0_112_ORIG.txt
Step 1: Qualitatively compare two files
- Before we actually obtain lexical sophistication measures, compare two texts in terms of their lexical use.
- In pairs, describe the strengths and weakeness in vocabulary use.
Step 2: Hypothesis
- In what way is one text more lexically sophisticated than the other?
- Try to come up with characteristics that describe the
quality of word usein each text
- Try to come up with characteristics that describe the
Step 3: Pick two or three lexical sophistication variables
Enter the text into analyzer
We can also compare two texts in simple text analyzer.
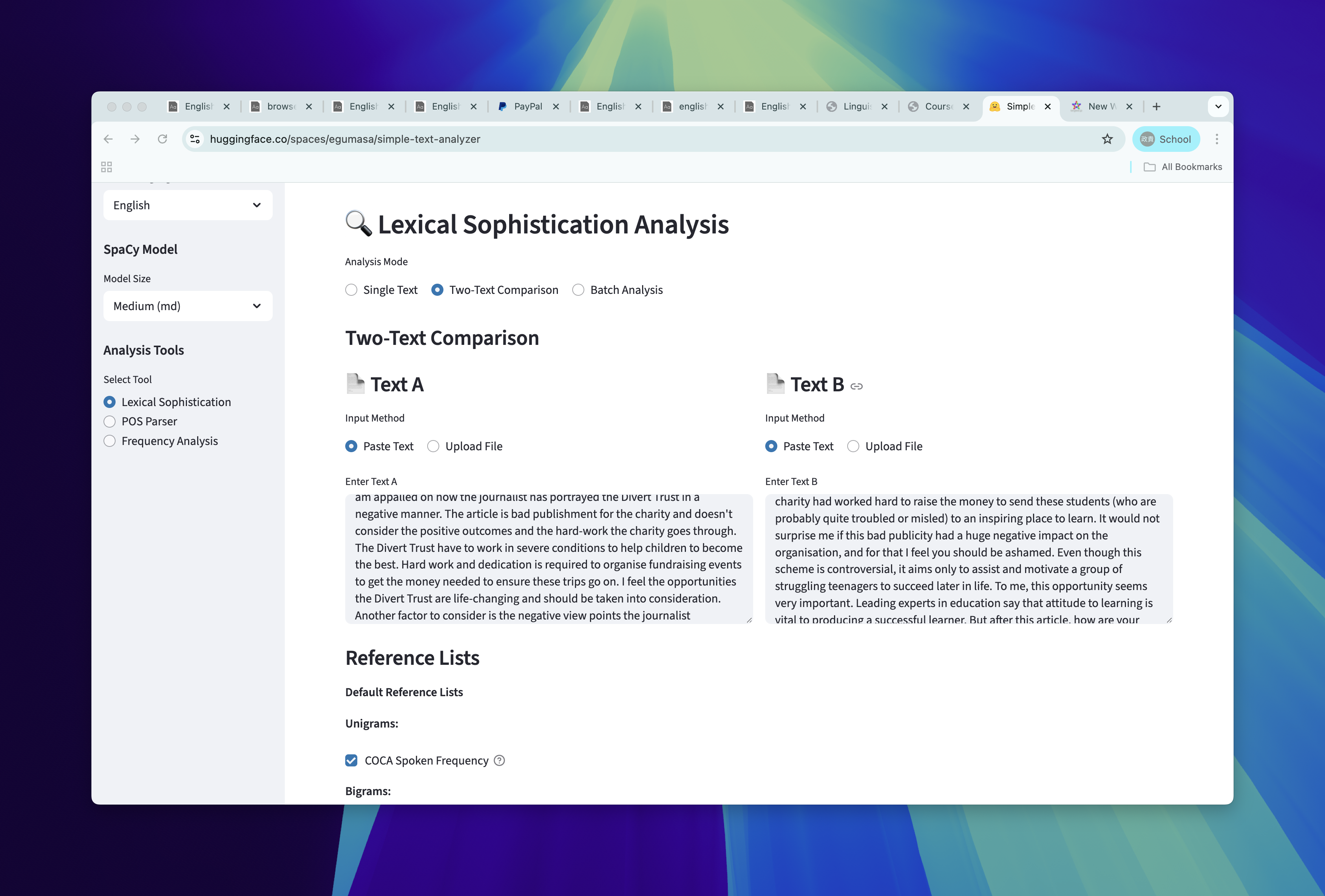
two-text
Step 4: Run analyses
Plots that compares two lists
!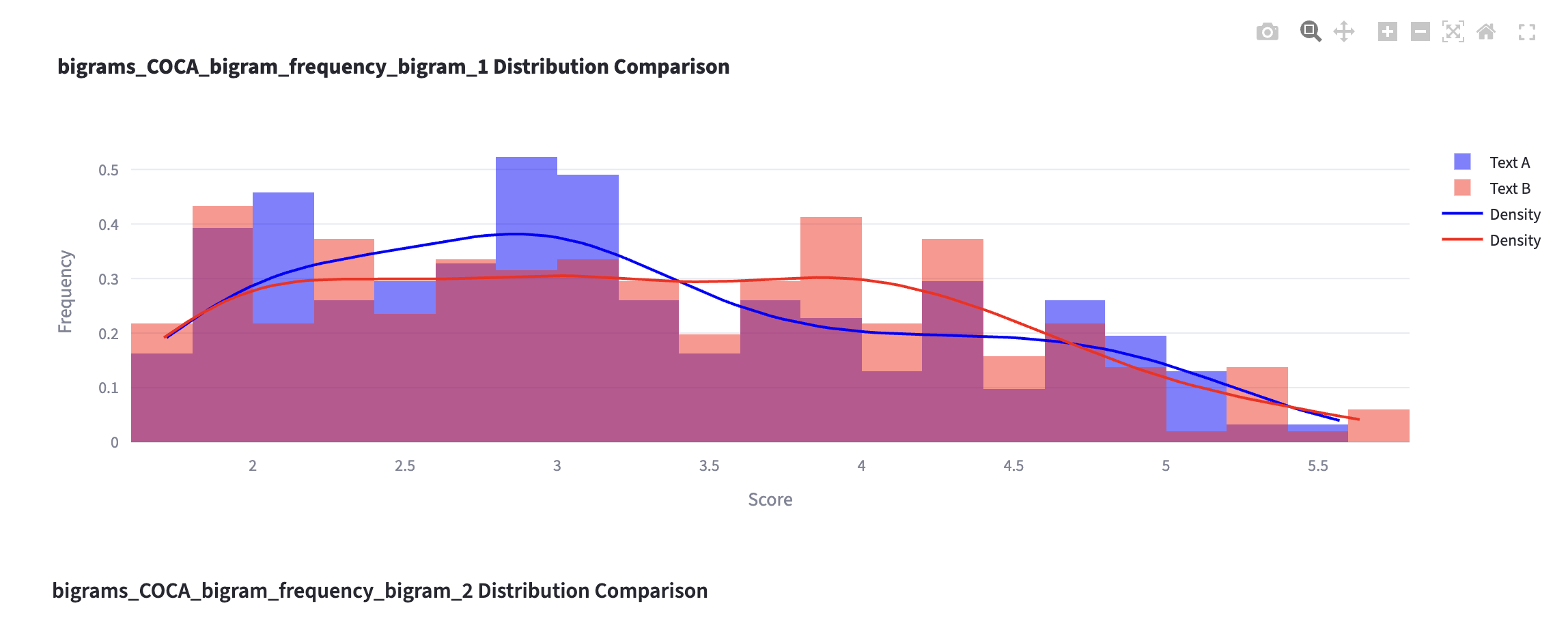
Step 5: Interpret the findings
- Let’s discuss how the two text differ in lexical use from one another.
- Use the tables with token information and visualization to (dis)confirm your hypothesis
Success Criteria
Your submission …
🎯 Learning Objectives
By the end of this session, students will be able to:
- Explain different types of multiword units: collocation, n-grams, lexical bundles
- Demonstrate how major association strengths measures (t-score, Mutual Information, and LogDice) are calculated using examples
Lexical Richness
- Lexical Diversity
- Lexical Sophistication
→ These are not sufficient for complete analysis of learner language.
Remember the comparisons?
Which one do you think reflect “better” vocabulary use?
Is important for college students to have a part-time job? I think that has much opinion to answer it. The part-time job is a job that can do in partial time. So the college student can do part-time job when they has spare time (if they want). There are many reasons why the college student do part-time job (if they do).
I find it hard to make a generalisation on whether it’s important or not for college students to have a part-time job, because this seems like something very individual and highly dependent on the individual student and their circumstances. Jobs serve a few main functions: to earn money, to gain experience, to get a head-start in a career, and to have something to do.
Rich vocabulary use?
- college students
- have a part-time job
- much opinion to answer
- partial time
- spare time
- many reasons
- make a generalisation on
- this seems like
- something very individual
- highly dependent on
- circumstances.
- serve functions
Phraseology is an important addition
- Research suggests that learners need to know “how to combine words”.
- Phraseological complexity (Paquot, 2019)
- We will talk about it more later…
- Paquot, M. (2018). Phraseological Competence: A Missing Component in University Entrance Language Tests? Insights From a Study of EFL Learners’ Use of Statistical Collocations. Language Assessment Quarterly, 15(1), 29–43. https://doi.org/10.1080/15434303.2017.1405421
- Paquot, M. (2019). The phraseological dimension in interlanguage complexity research. Second Language Research, 35(1), 121–145. https://doi.org/10.1177/0267658317694221
Usage-based learning
- The idea that item-based learning facilitate acquisition of systematic aspects of language.
- Repeated exposure leads to abstraction of the schematic language unit.
- So usage/exposure in communicative contexts allows the learner to extract grammatical rules/learn how to express a concept.
Definitions and types of multiword sequences
Definitions
Multiword Unit/Sequence is a cover term for different things.
| Formula type | Description | Examples |
|---|---|---|
| Phrasal verbs | verbs followed by an adverbial particle, where the phrase as a whole is used with a non-literal meaning | blow up, shut down |
| Idioms | a relatively fixed sequence of words with a non-literal, typically metaphorical meaning | kick the bucket |
| Binomials | recurrent conventional phrase of two words from the same POS, connected by a conjunction | black and white |
| Pragmatic formulas | context-bound phrases that are characteristic of a particular speech community | thank you, bless you |
Definitions
| Formula type | Description | Examples |
|---|---|---|
| Collocations | Pairs of words that are syntagmatically associated | take time, young people |
| Lexical bundles | Contiguous word combinations which occur very frequently in language | in other words |
| Lexicalized sentence stems | A conventional expression in whih some elements are fixed and others allow for a range of possibilities | what I want you to do is |
Approaches to define and operationalize MWUs
We have two major approaches to define MWUs:
| Approach | Description |
|---|---|
| Frequency-based | Quantifies the degree of associations between component words |
| Phraseological | Involves human judgement to focus on semantic transparency, non-compositionality, and/or fixedness. |
- We will follow
frequency-based approachin this course.
Preview discussion
- Which of the following type of MWUs are more challenging to identify from the frequency-based approach?
- Collocation:
play + role,meet + expectation - Binomials:
black and white - Idiom:
kick the bucket,over the moon - Lexical bundles:
in terms of the,the extent to which
- Collocation:
Questions?
Extracting multiword sequences
Recurrence and co-occurrence
Recurrence
Extracting recurrent units
We can extract recurrent units by:
- Counting the number of contigous sequences over a reference corpus
- Manually filter them OR measuring Strengths Of Association
N-grams
- N-grams: contiguous sequences of n words
- Take N-words using a sliding window approach.
Example: I have not had Gyutan yet this time.
Bigram: [I have] [have not] [not had] ... [this time].
Trigram: [I have not] [have not had] [not had Gyutan] ...
Top 12 N-grams in BROWN corpus
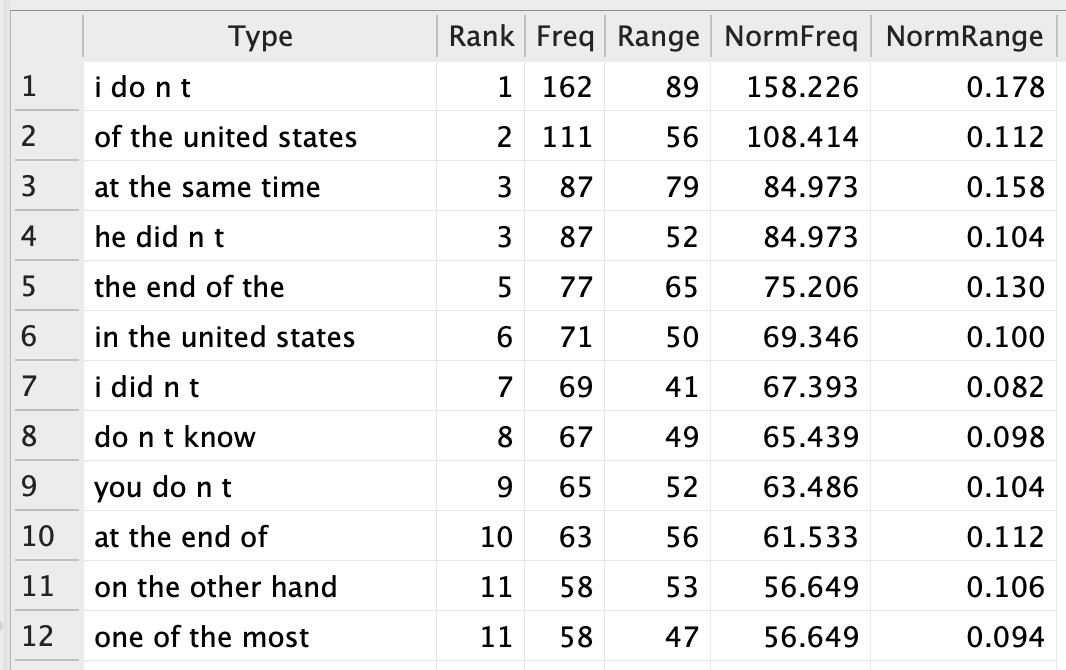
4-grams corpus
N-grams in BROWN corpus (111th - 122nd)
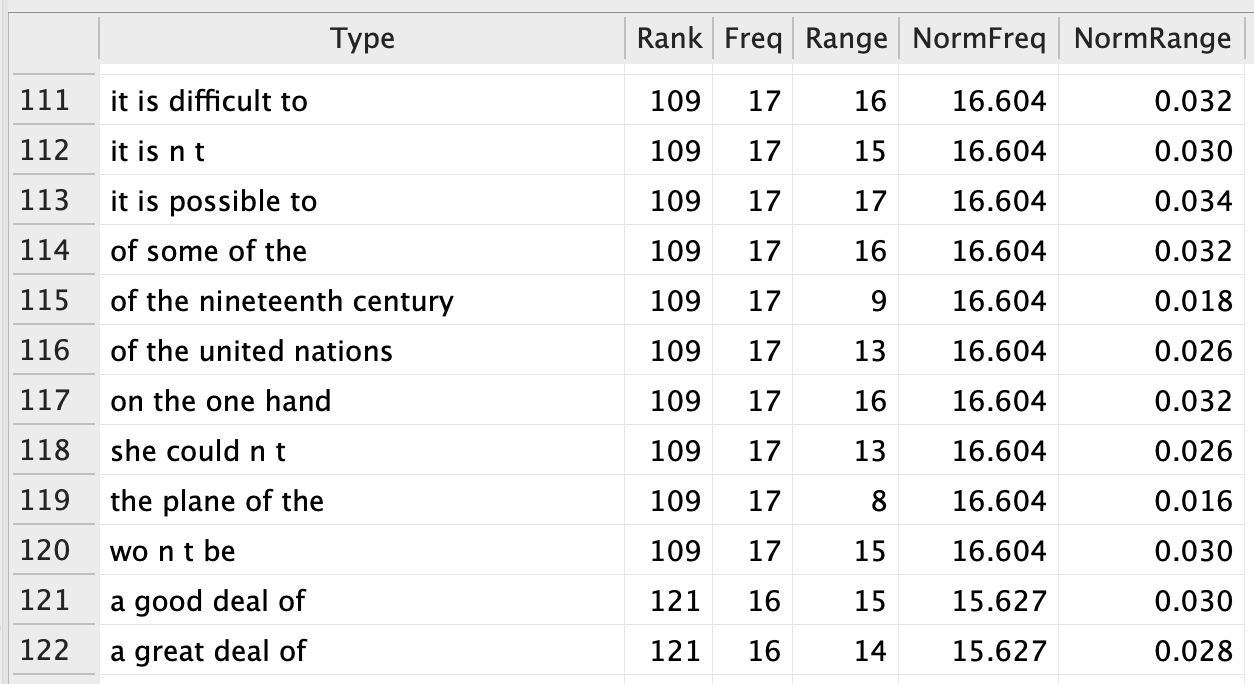
4-grams from 111-122
Lexical bundles
- “Fixed sequence of words that recur frequently”
- Essentially, N-grams plus manual filtering and categorization
- Biber (2004) identified lexical bundles from
Classroom teaching,Textbooks,ConversationandAcademic prose![]()
T2K-SWAL
- Biber, D. (2004). If you look at …: Lexical Bundles in University Teaching and Textbooks. Applied Linguistics, 25(3), 371–405. https://doi.org/10.1093/applin/25.3.371
T2K-SWAL corpus
- Attempts to represent university language
| Perspective | Example |
|---|---|
| Genre representation | “classroom teaching, office hours, study groups, on-campus service encounters, textbooks, course packs, and other written materials e.g. university catalogues, brochures.” (Biber et al., 2004) |
| Disciplines | Business, Education, Engineering, Humanities, Natural Science, and Social Science |
| Educational level | Lower devision undergrad, Upper devision undergrad, and Graduate. |
| Regional variation | Northern Arizona University, Iowa State University, California State University at Sacramento, Georgia State University |
Methods to identify lexical bundles
- Used n-grams to compile a first list.
- Filtered the list with 40 times per million threshold.
- Kept four-word sequences
- Range requirements was set to 5 texts.
Communicative Functions
- Biber et al. (2004) presented three important “functions” of bundles
| Function | Description | Example |
|---|---|---|
| Referential | Sequences that “makes direct referents to physical or abstract entities”. | there's a lot of, a little bit of, in terms of the, as a result of |
| Stance | “expresses attitudes or assessments of certainty that frame some other proposition” | I don't know if, are more likely, you might want to, it is important to |
| Discourse organizer | signals textual relations between current and previous/upcoming discourse | if you look at, let's have a look, I mean you know |
Classify the following bundles into three categories
- Choice:
Referential,Stance,Discourse
| Bundle | Category |
|---|---|
| on the other hand | |
| I don’t know how | |
| greater than or equal | |
| you have to be |
Practical considerations
To be able to identify interesting recurrent patterns
- The size of the corpus;
- lengths of each text in your corpus
- Representation of genre, topic, register
- Reliability issue of manual classification of functions
Summary of recurrent units
- N-gram search (counting contiguous sequences of n-words) allows recurrent linguistic patterns to emerge.
- N-grams serve as first list for lexical bundle.
- Lexical bundles are automatically identified, then filtered with frequency.
- They are manually classified into functional categories.
Co-occurrence
Extracting co-occurring units OR Collocations
When we talk about co-occurrence, things are a bit more complex.
- Let’s consider
meet + expectation - Can you make 3 sentences using this collocation?
Examples from you
- The results of the experiment didn’t meet my expectation.
- The results met the expectation that I have made before the experiment.
- We hope the new policy will meet the public expectation.
- The expectation of the univerity was met.
The nature of collocation
- Collocation is about “preferences based on conventional uses”
- “Semantic priming” (Hoey, 2005)
Window-based approach (Basic)
- Window-based approach is most widely used (including AntConc).
It counts the number of words within a specified window
e.g., +/- 4 words window = counts items 4 words before and after the node word.
I strongly think the expectation was met for the ... [L4] [L3] [L2] [L1] [ node ] [R1] [R2] [R3] [R4]
- This is called surface-level co-occurrences (Evert, 2008)
Window-based approach
Sometimes, the collocates can be more distant.
I strongly think the expectation for the final exam was met .... [L4] [L3] [L2] [L1] [ node ] [R1] [R2] [R3] [R4] [???]Cannot capture this unless we expand the window….
But this raises trade-off between noises and more accurate retrieval.
Dependency Parsing (Advanced)
- More recent research uses Syntactic co-occurrences
- We can parse grammatical relations using dependency parsing
- Dependency parsing (係受け解析) (more details tomorrow) can indicate grammatical relations between words.
Dependency Parsing (Advanced)
- With dependency, we can capture
meet + expectationaccurately (even if they are far away).
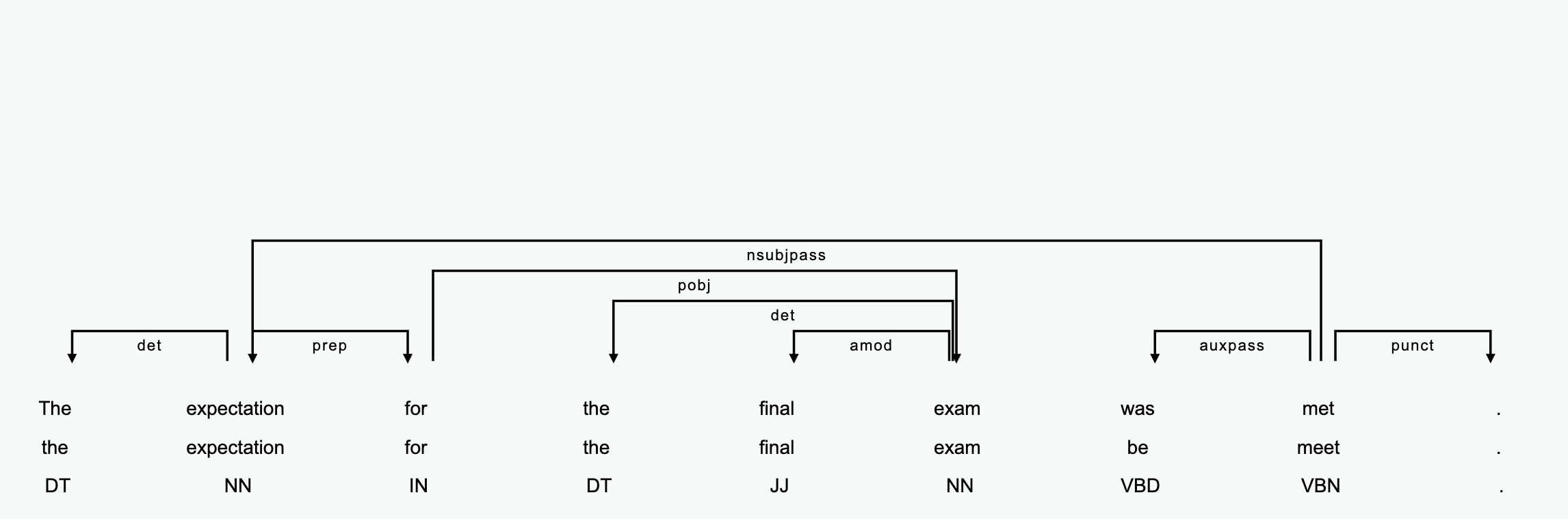
Dependency Parsing example
Typical dependency relations for lexical collocations
A few depedency labels are useful to identify collocations
| Dependency label | Name | Example |
|---|---|---|
amod |
Adjectival Modifier | significant + change |
dobj |
Direct Object | play + role in active voice (play a role) |
nsubjpass |
Nominal subject of a passive construction | play + role in passive voice (role is played) |
advmod |
Adverbial modifier | change + incrementally |
Summary for co-occurrence
There are two main ways to capture co-occurrence
- Window-based approach (AntConc)
- Dependency-based approach (needs advanced NLP tools; but we will cover).
Operationalizing association
Why is frequency not sufficient?
Discuss:
- Researchers say that frequency alone is not sufficient to identify useful multiword sequences. Why?
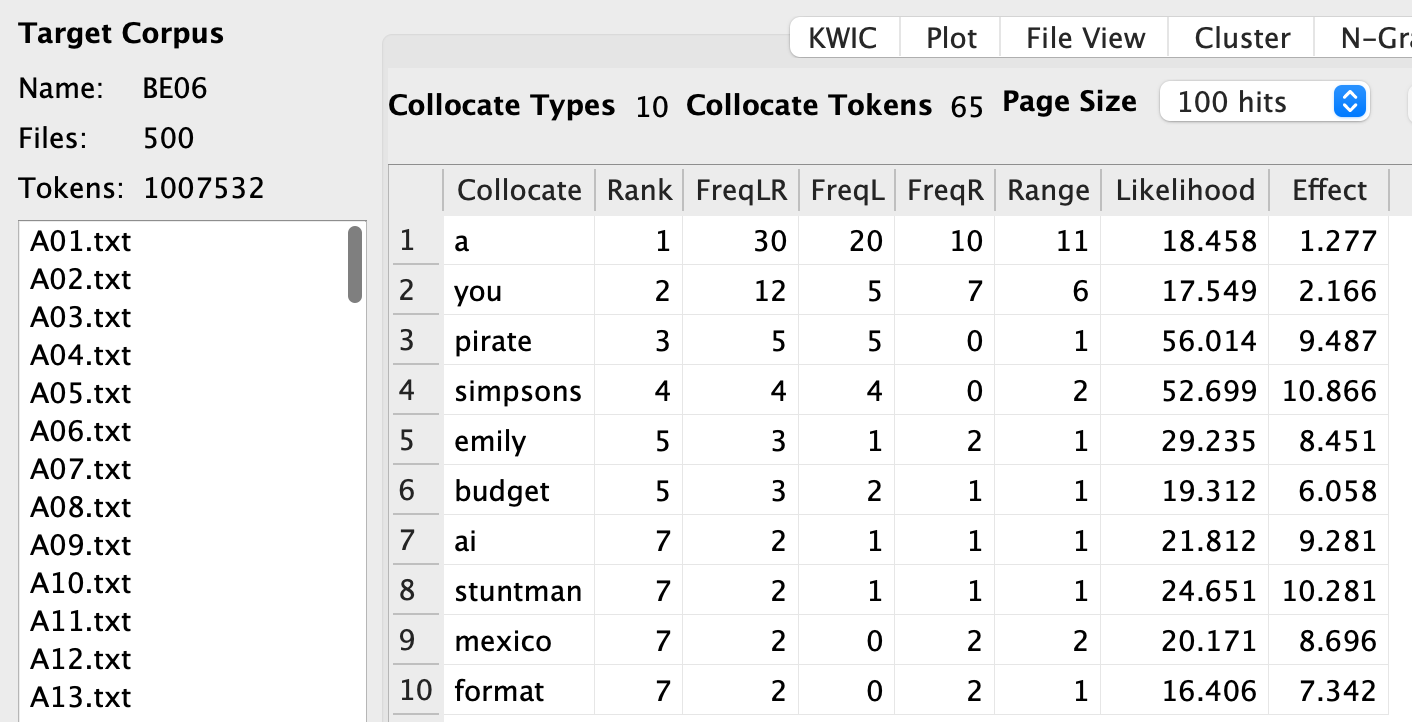
collocation-freq
Strengths Of Association Measures
The issue: A word can co-occur just because they are frequent by default.
Strengths Of Association (SOA) provides ways to take “frequency” of individual words account.
Several SOA measures are commonly used (Gablasova et al., 2017).
- T-score
- Mutual Information
- LogDice
Now let’s first look at expected cooccurrences.
Mathematical look into collocational association
When we think about “association”, we can think about it from a probability perspective.
| # with word 1 | # without word 1 | |
|---|---|---|
| # with word 2 | Frequency of collocation | Remaining frequency of word 2 |
| # without word 2 | Remaining frequency of word 1 | Rest of corpus size |
Suppose we have following
- Collocation freq: 50
- Word 1: 500
- Word 2: 500
- Entire corpus: 1,000,000
| # with word 1 | # without word 1 | Total | |
|---|---|---|---|
| # with word 2 | 50 | 450 | 500 |
| # without word 2 | 450 | 999,050 | 999,500 |
| Total | 500 | 999,500 | 1,000,000 |
Expected Ocurrences (Corrected)
- Expected co-occurrences are usually calculated as follows: \[E_{11} = {(\text{freq of node word} * \text{freq of collocate } ) \over Corpus size}\]
Let’s calculate the expected frequency.
- If word1 and word 2 occur 500 times each in a million word corpus…
Mutual Information
Now we are ready to calculate MI.
- The expected frequency = .25
- The observed frequency = 50
\[MI = {log_2{ \text{Observed freq} \over \text{Expected frequency} }}\]
Let’s do this:
Mutual Information
MI is the ratio between observed and expected frequency in logarithmic scale.
\[MI = {log_2{ \text{Observed freq} \over \text{Expected frequency} }}\]
T-score
T-score is calculated as follows:
- \(\text{T-score} = {\text{Observed} - \text{Expected} \over \sqrt{Observed}}\)
Using the same numbers:
LogDice
- LogDice is somewhat different in calculation.
- It does not use Expected frequency
- That is, it does not rely on “corpus size” normalization.
\(\text{log Dice} = 14 + \log_2( {{2 \times Observed} \over {R_1 + C_1}})\)
Summary
- Major association measures are MI, T-score, and LogDice.
- We covered how to calculate each.
Phraseological complexity
Phraseological complexity
Paquot (2019): “the range of phraseological units that surface in language production and the degree of sophistication of such phraseological units” (p. 124)
| Constructs | Description |
|---|---|
| Phraseological diversity | “a (derived) type–token ratio representing the number of unique phraseological units to the total number of phraseological units, by analogy with the measurement of lexical diversity.” (p. 125) |
| Phraseological sophistication | “the selection of word combinations that are ‘appropriate to the topic and style of writing, rather than just general, everyday vocabulary’” (p. 125) |
- Paquot, M. (2018). Phraseological Competence: A Missing Component in University Entrance Language Tests? Insights From a Study of EFL Learners’ Use of Statistical Collocations. Language Assessment Quarterly, 15(1), 29–43. https://doi.org/10.1080/15434303.2017.1405421
- Paquot, M. (2019). The phraseological dimension in interlanguage complexity research. Second Language Research, 35(1), 121–145. https://doi.org/10.1177/0267658317694221
Operationalizing Phraseological Diversity
- Not much progress compared to lexical diversity.
- Paquot (2019) uses RootTTR for operationalization
- PU = Phraseological unit
\(\text{Diversity of PU} = {\text{Type of PU} \over \sqrt{\text{Token of PU}}}\)
- Given the findings on lexical sophistication, an application of Moving-Average could be interesting.
Operationalizing Phraseological Sophistication
- As with lexical sophistication measures, typically
Meanis typically used.
\(\text{Sophistication of PU} = {\text{Total score for SOAs} \over \text{# of Token with SOA values}}\)
- e.g.,\(\text{Mean MI for amod} = {\text{Total MI score for amod} \over \text{# of amod pairs with MI}}\)
Basic findings
- Recent studies demonstrate benefits of adding phraseological complexity measures to explain second language proficiency:
- Eguchi & Kyle (2020) in Oral Proficieincy Interview
- Paquot (2019): Dependency collocation explained more variance than syntactic complexity
- Kyle & Eguchi (2021): Dependency-based collocation explained TOEFL speaking scores more than n-gram measures.
- More research should integrate Phraseological Complexity more in explaining developmental patterns
- e.g., Siyanova & Spina (2020)
- Paquot, M. (2019). The phraseological dimension in interlanguage complexity research. Second Language Research, 35(1), 121–145. https://doi.org/10.1177/0267658317694221
- Eguchi, M., & Kyle, K. (2020). Continuing to Explore the Multidimensional Nature of Lexical Sophistication: The Case of Oral Proficiency Interviews. The Modern Language Journal, 104(2), 381–400. https://doi.org/10.1111/modl.12637
- Kyle, K., & Eguchi, M. (2021). Automatically assessing lexical sophistication using word, bigram, and dependency indices. In Perspectives on the L2 phrasicon: The view from learner corpora (pp. 126–151).
- Siyanova‐Chanturia, A., & Spina, S. (2020). Multi‐Word Expressions in Second Language Writing: A Large‐Scale Longitudinal Learner Corpus Study. Language Learning, 70(2), 420–463. https://doi.org/10.1111/lang.12383
Summary
- Corpus-based approach can look at recurrence and co-occurrence
- A central methods to the recurrence is n-gram search
- For co-occurence, we have window-based (surface) and dependency-based (syntactic) collocations.
- SOA allows you to quantify how strongly associated two words are
What questions do you have?
Linguistic Data Analysis I