Session 9: Learner Corpus Mini-Research
Housekeeping
🎯 Learning Objectives
As a wrap-up of the vocabulary and multiword sessions, you will be able to:
- Conduct mini learner corpus research.
- Construct several learner corpus research questions with structured support.
- Choose a learner corpus that suit your research needs
- Justify choices of lexical richness measures to investigate a research questions
- Compute lexical richness indices and analyze the results to answer research questions
- Present the results and interpretation of the findings in a written prose
Mini-research outline
- Construct research questions
- Understand and choose the learner corpus
- Construct hypothesis
- Select index
- Compute the index
- Conduct analysis
- Interpret and write-up the results
Step 1: Construct research questions
Researchers typically set RQs about the relationships between lexical characteristncs and variables that defines subsection of the corpus (e.g., grade, genre, or proficieincy score).
Step 2: Understand and choose the corpus
In this assignment, please choose one of the following corpora:
- Growth in Grammar (GiG) corpus (Durrant, 2023)
- ICNALE corpus (Edited Essay OR GRA)
- If you have a corpus you want to analyze, let Masaki know!
Understanding the corpus contents
- You can look at followings:
- meta-data (the additional information about the corpus files)
- several text files
GiG corpus
- For detailed information, see Table 2.1 in Durrant (2023)
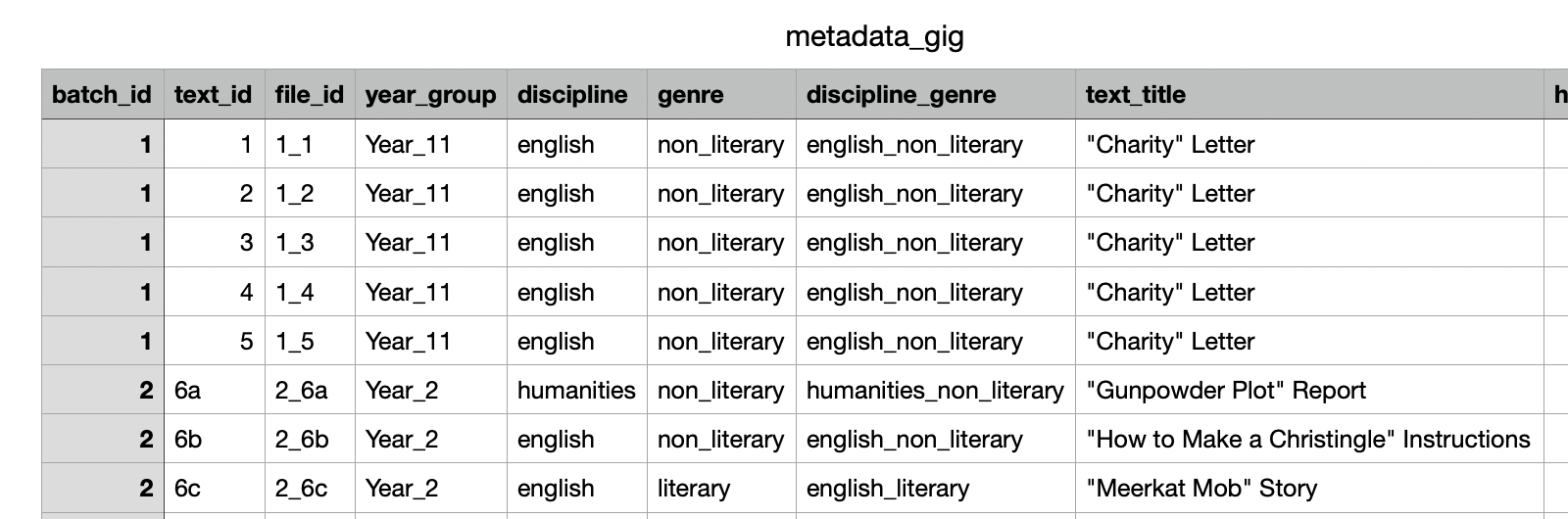
GiG metadata
ICNALE GRA
ICNALE GRA documents 120 essays evaluated by 80 people. - These 80 people are from different backgrounds. - You can basically use average essay ratings.
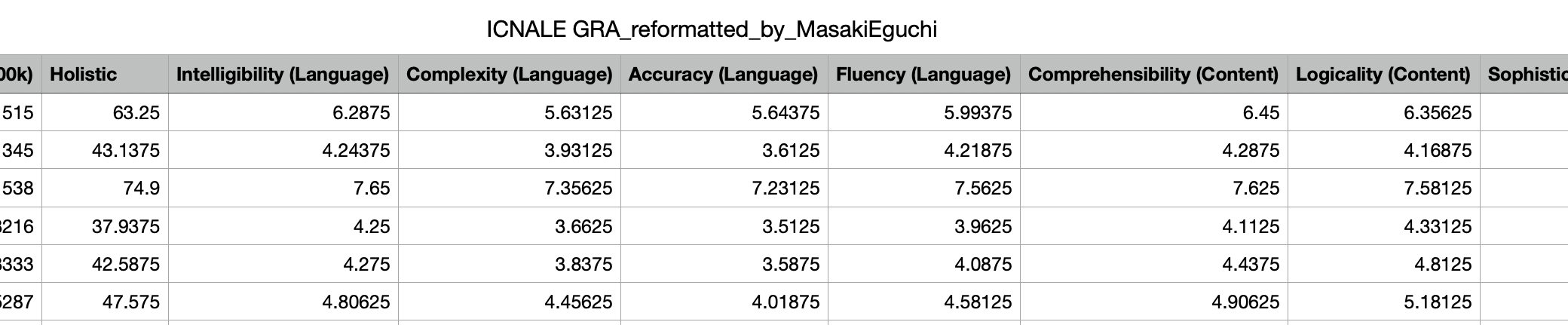
ICNALE metadata
Step 1 & 2: Formluating research questions
What would you like to know?
How learners develop their language ability across time?
What defines “more proficient” language use?
How situational variables of writing/speaking impact the language production?
How does production of X change across time/proficiency?
Anything else?
Do not forget to specify constructs!
Step 2: Choosing a right corpus
Based on the research question, which corpus should you choose?
- Growth in Grammar (GiG) corpus (Durrant, 2023)
- ICNALE corpus (Edited Essay OR GRA)
- Understand what it offers and doesn’t.
- Pick one corpus to move forward.
Step 3: Construct hypothesis
- Once you’ve articulated broad research questions and chose a corpus, speculate on possible results.
- Use what you’ve learned so far about lexical richness.
- Lexical diversity
- Lexical sophistication
- Phraseological complexity
- Which ones are relevant to your questions?
Step 4: Select index
Let’s keep going!
Specifically, which index may capture the change in the vocabulary use in your context?
- List posssible indices to capture the differences in vocabulary use.
- Why do you think those are good choices?
Step 5: Compute the index
Okay now it’s time to do some analysis!
- Which ones are you going to use:
- TAALED
- TAALES
- Lexical profiler
- Custom list in Simple Text Analyzer?
Step 6: Conduct analysis
Once you obtained the indices, it’s time to understand the pattern by plotting.
- Use simple analyzer to plot data from:
- GiG corpus
- ICNALE
- The simple text analyzer is made for that purpose.
Step 7: Interpret and write-up the results
Now you understand what is happening in your corpus, you can write that up.
Mini-research outline
- Construct research questions
- Understand and choose the learner corpus
- Construct hypothesis
- Select index
- Compute the index
- Conduct analysis
- Interpret and write-up the results
Let’s work!
Let us know if you have any questions.
Reflection
- You can now:
- Provide reasons for your choice of lexical richness measures.
- Conduct preliminary analysis to understand how text differ from one aother in relation to learner’s proficiency, learner groups, etc.
Linguistic Data Analysis I